简介
Dirsearch是一个用 Python 编写的命令行工具,设计用于通过使用字典攻击的方式扫描Web服务器上的目录和文件。它可以帮助渗透测试人员、红队、安全研究员等发现服务器上未公开的资源和潜在漏洞。
使用
安装方法
KALI安装
![Pasted-image-20250111163831]()
pip下载
![Pasted-image-20250111164252]()
Github下载
git clone https://github.com/maurosoria/dirsearch.git
cd dirsearch
pip install -r requirements.txt
python dirsearch.py
|
![Pasted-image-20250111164838]()
相关参数
基本格式
dirsearch -u <target_url> [options]
|
必选内容
-u指定目标url-l指定url文件-s扫描进度保存的会话文件(可不选,不指定默认不开启)
参数参考表
Mandatory(必选)
| 参数 |
说明 |
-u URL, --url=URL |
目标 URL(s),可以使用多个标志指定多个 URL。 |
-l PATH, --url-file=PATH |
URL 列表文件。 |
--stdin |
从 STDIN 读取 URL(s)。 |
--cidr=CIDR |
目标 CIDR。 |
--raw=PATH |
从文件加载原始 HTTP 请求(使用--scheme 标志设置协议)。 |
-s SESSION_FILE, --session=SESSION_FILE |
会话文件。 |
--config=PATH |
配置文件的完整路径,默认是config.ini。 |
Dictionary Settings(字典设置)
| 参数 |
说明 |
-w WORDLISTS, --wordlists=WORDLISTS |
自定义字典(多个字典用逗号分隔)。 |
-e EXTENSIONS, --extensions=EXTENSIONS |
扩展名列表(用逗号分隔,例如:php,asp)。 |
-f, --force-extensions |
将扩展名添加到每个字典项的末尾。默认情况下,dirsearch 只会替换 %EXT% 关键字为扩展名。 |
-O, --overwrite-extensions |
使用-e 指定的扩展名覆盖字典中的其他扩展名。 |
--exclude-extensions=EXTENSIONS |
排除的扩展名列表(用逗号分隔)。 |
--remove-extensions |
移除路径中的扩展名(例如admin.php -> admin)。 |
--prefixes=PREFIXES |
向所有字典项添加自定义前缀(用逗号分隔)。 |
--suffixes=SUFFIXES |
向所有字典项添加自定义后缀(忽略目录,多个后缀用逗号分隔)。 |
-U, --uppercase |
将字典中的词转换为大写。 |
-L, --lowercase |
将字典中的词转换为小写。 |
-C, --capital |
将字典中的词转换为首字母大写。 |
General Settings(通用设置)
| 参数 |
说明 |
-t THREADS, --threads=THREADS |
设置线程数。 |
-r, --recursive |
启用递归模式,扫描子目录路径。 |
--deep-recursive |
在每个目录深度上都执行递归扫描(例如:api/users -> api/)。 |
--force-recursive |
对每个找到的路径都执行递归扫描,不仅仅是目录。 |
-R DEPTH, --max-recursion-depth=DEPTH |
设置最大递归深度。 |
--recursion-status=CODES |
指定有效的状态码,用于递归扫描(支持范围,例如200, 300-399)。 |
--subdirs=SUBDIRS |
扫描指定 URL 的子目录(多个子目录用逗号分隔)。 |
--exclude-subdirs=SUBDIRS |
排除指定子目录进行递归扫描(多个子目录用逗号分隔)。 |
-i CODES, --include-status=CODES |
包含状态码,多个状态码用逗号分隔,支持范围(例如200,300-399)。 |
-x CODES, --exclude-status=CODES |
排除状态码,多个状态码用逗号分隔,支持范围(例如301,500-599)。 |
--exclude-sizes=SIZES |
排除某些响应大小的路径,多个大小用逗号分隔(例如0B,4KB)。 |
--exclude-text=TEXTS |
排除响应中包含指定文本的路径,可以使用多个标志。 |
--exclude-regex=REGEX |
排除响应中匹配正则表达式的路径。 |
--exclude-redirect=STRING |
排除响应中包含指定重定向 URL 的路径(例如/index.html)。 |
--exclude-response=PATH |
排除与此页面响应类似的路径,输入路径作为示例(例如404.html)。 |
--skip-on-status=CODES |
在遇到这些状态码时跳过目标,多个状态码用逗号分隔,支持范围。 |
--min-response-size=LENGTH |
只扫描大于指定响应长度的路径(例如100B、4KB)。 |
--max-response-size=LENGTH |
只扫描小于指定响应长度的路径(例如100B、4KB)。 |
--max-time=SECONDS |
设置扫描的最大运行时间(秒)。 |
--exit-on-error |
一旦遇到错误则退出扫描。 |
Request Settings(请求设置)
| 参数 |
说明 |
-m METHOD, --http-method=METHOD |
设置 HTTP 请求方法,默认为GET。 |
-d DATA, --data=DATA |
设置 HTTP 请求的正文数据,通常用于POST 请求。 |
--data-file=PATH |
从文件加载 HTTP 请求数据。 |
-H HEADERS, --header=HEADERS |
设置 HTTP 请求头部,可以使用多个标志。 |
--header-file=PATH |
从文件加载 HTTP 请求头部。 |
-F, --follow-redirects |
跟随 HTTP 重定向。 |
--random-agent |
每个请求使用随机的 User-Agent。 |
--auth=CREDENTIAL |
设置身份验证凭证,格式为user:password 或 bearer token。 |
--auth-type=TYPE |
设置身份验证类型(如:basic、digest、bearer、ntlm、jwt、oauth2)。 |
--cert-file=PATH |
从文件加载客户端证书。 |
--key-file=PATH |
从文件加载客户端证书的私钥(未加密)。 |
--user-agent=USER_AGENT |
设置自定义 User-Agent。 |
--cookie=COOKIE |
设置 HTTP 请求的 Cookie。 |
Connection Settings(连接设置)
| 参数 |
说明 |
--timeout=TIMEOUT |
设置连接超时。 |
--delay=DELAY |
设置请求之间的延迟。 |
--proxy=PROXY |
设置代理 URL(HTTP/SOCKS),可以使用多个标志。 |
--proxy-file=PATH |
从文件加载代理服务器。 |
--proxy-auth=CREDENTIAL |
设置代理认证凭证。 |
--replay-proxy=PROXY |
使用代理回放找到的路径。 |
--tor |
使用 Tor 网络作为代理。 |
--scheme=SCHEME |
设置协议(当 URL 中没有协议时使用)。 |
--max-rate=RATE |
设置每秒最大请求数。 |
--retries=RETRIES |
设置失败请求的重试次数。 |
--ip=IP |
设置服务器的 IP 地址。 |
Advanced Settings(高级设置)
| 参数 |
说明 |
--crawl |
在响应中抓取新的路径。 |
View Settings(查看设置)
| 参数 |
说明 |
--full-url |
在输出中显示完整的 URL(在静默模式下自动启用)。 |
--redirects-history |
显示重定向历史。 |
--no-color |
禁用彩色输出。 |
-q, --quiet-mode |
静默模式,减少输出。 |
Output Settings(输出设置)
| 参数 |
说明 |
-o PATH, --output=PATH |
设置输出文件路径。 |
--format=FORMAT |
设置报告格式(可选:simple、plain、json、xml、md、csv、html、sqlite)。 |
--log=PATH |
设置日志文件路径。 |
基本参数使用
测试站点
- 我这里使用我的博客站点进行测试,为了速度我本地起了一个。
![Pasted-image-20250111171318]()
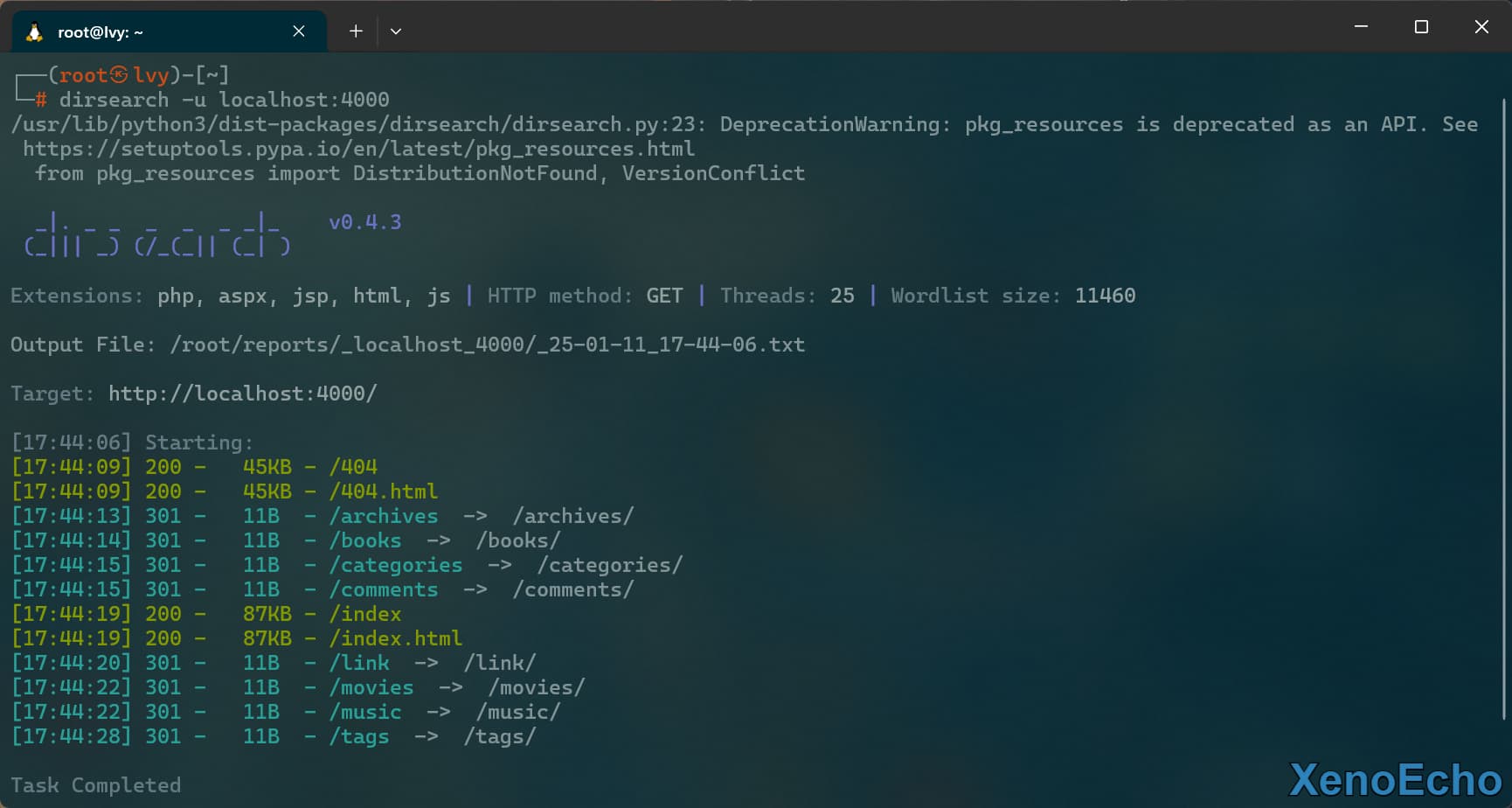
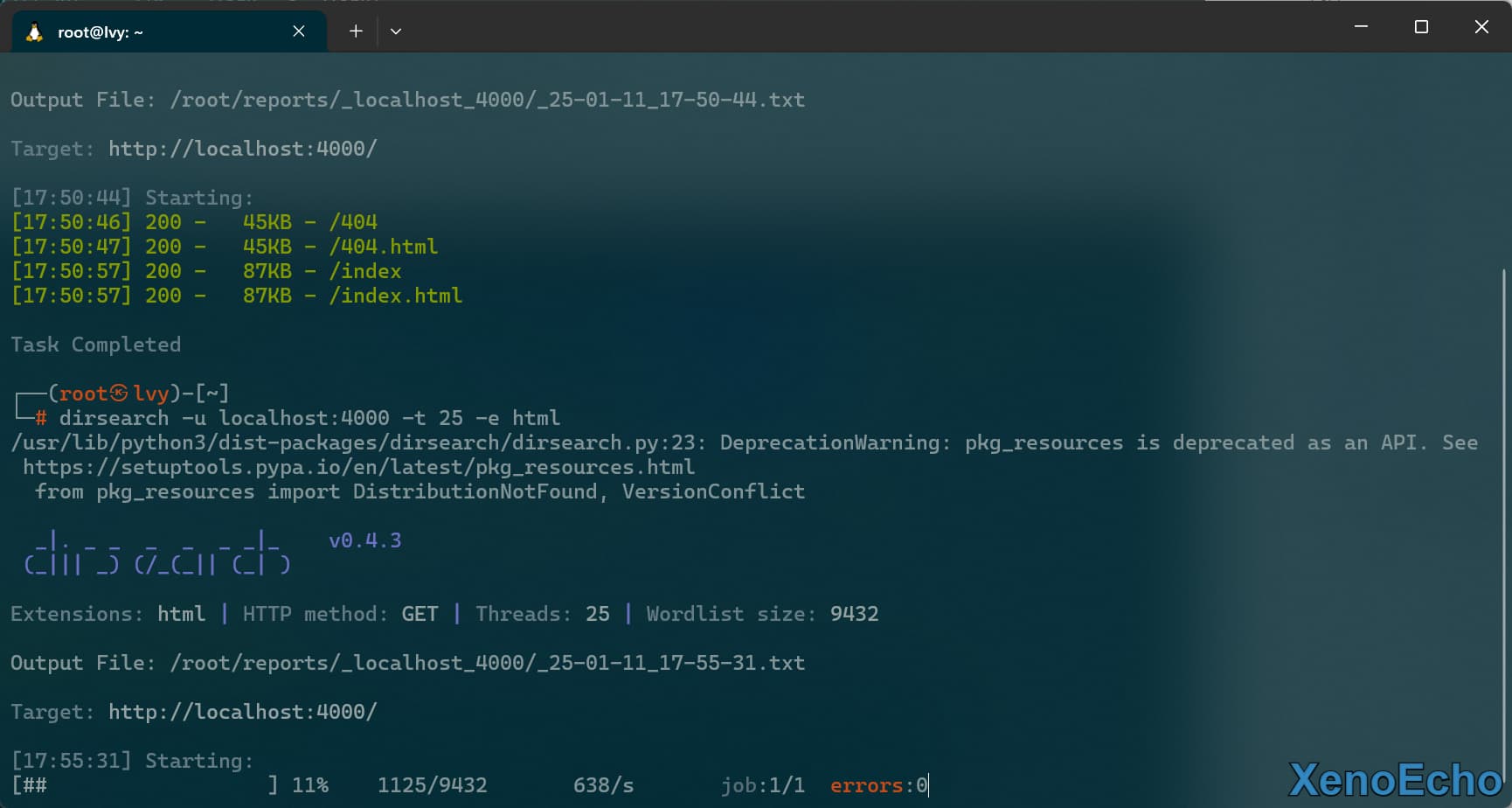
指定站点普通扫描
dirsearch -u localhost:4000
|
![Pasted-image-20250111174455]()
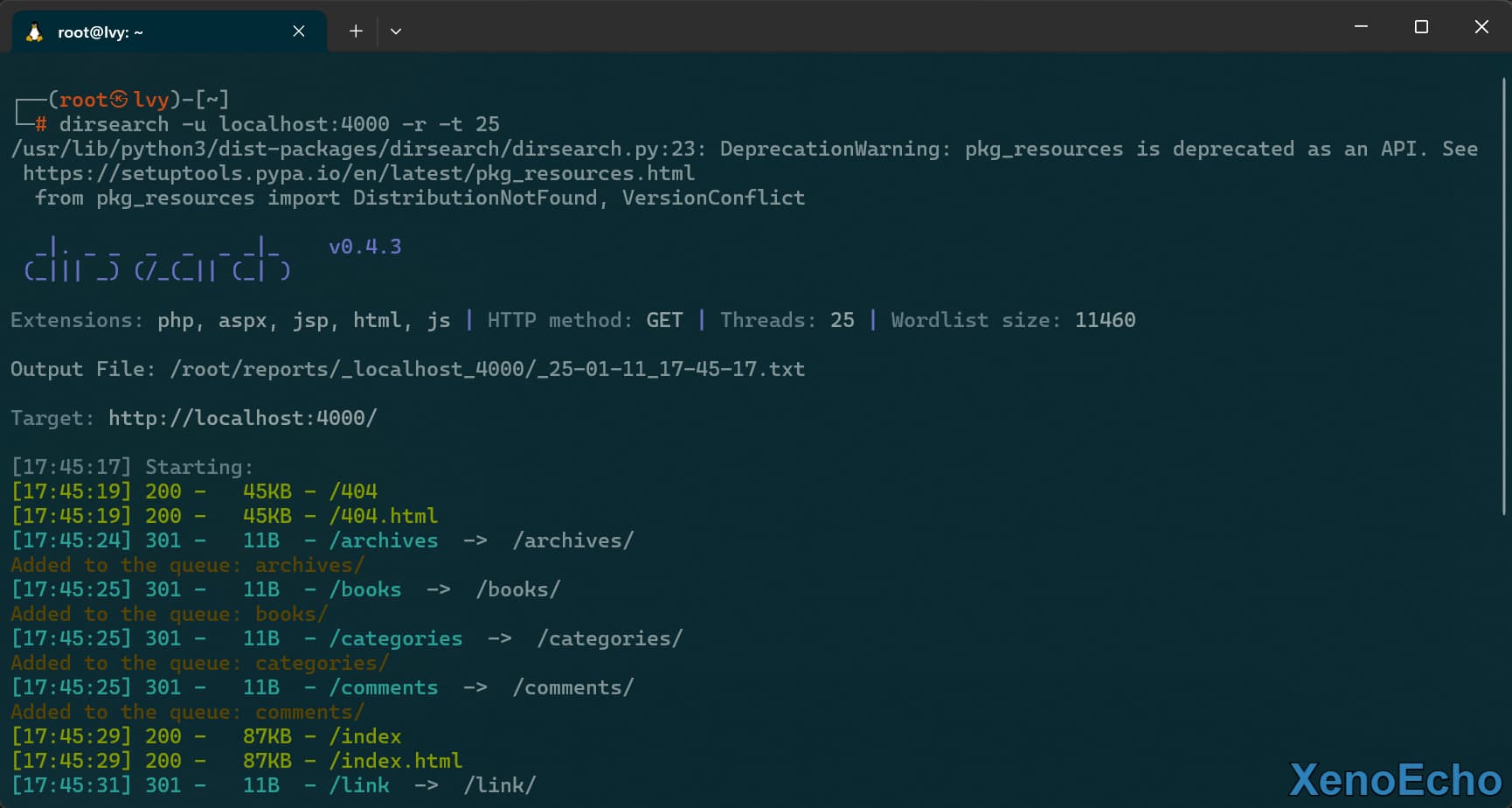
递归扫描
- 第一次扫描可以发现我有一些路径例如:
books,可以使用-r参数可以设置递扫描,-t设置扫描线程数。
dirsearch -u localhost:4000 -r -t 25
|
![Pasted-image-20250111174646]()
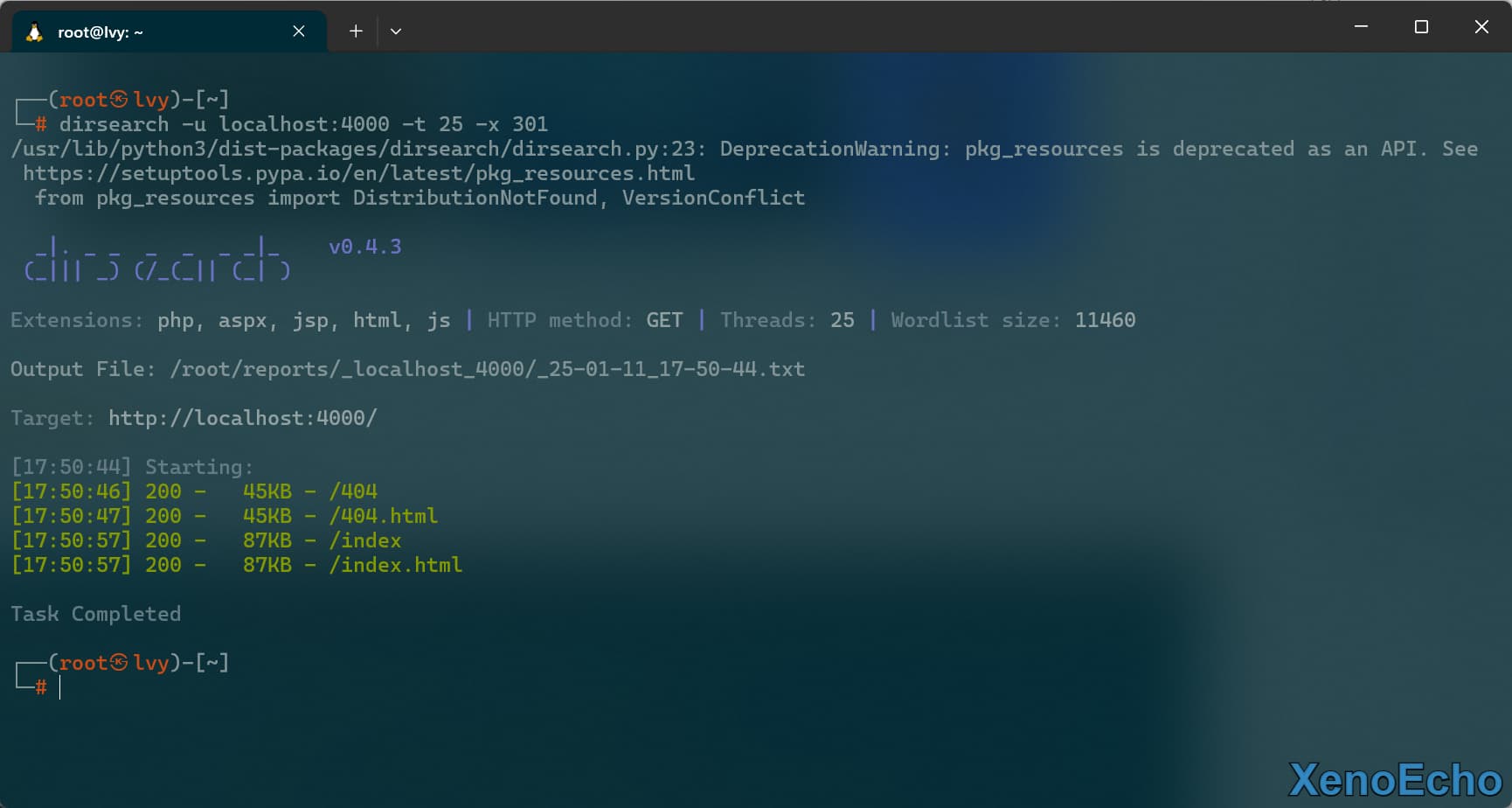
排除状态码
- 第一次扫描看到有一些
301的状态码,下面使用-x参数排除掉多个格式的话可以用,分开。
dirsearch -u localhost:4000 -t 25 -x 301
|
![Pasted-image-20250111175121]()
指定状态码
- 有排除肯定有指定了,使用
-i参数指定状态码,多个状态码用,分隔。
dirsearch -u localhost:4000 -t 25 -i 200
|
![Pasted-image-20250111175540]()
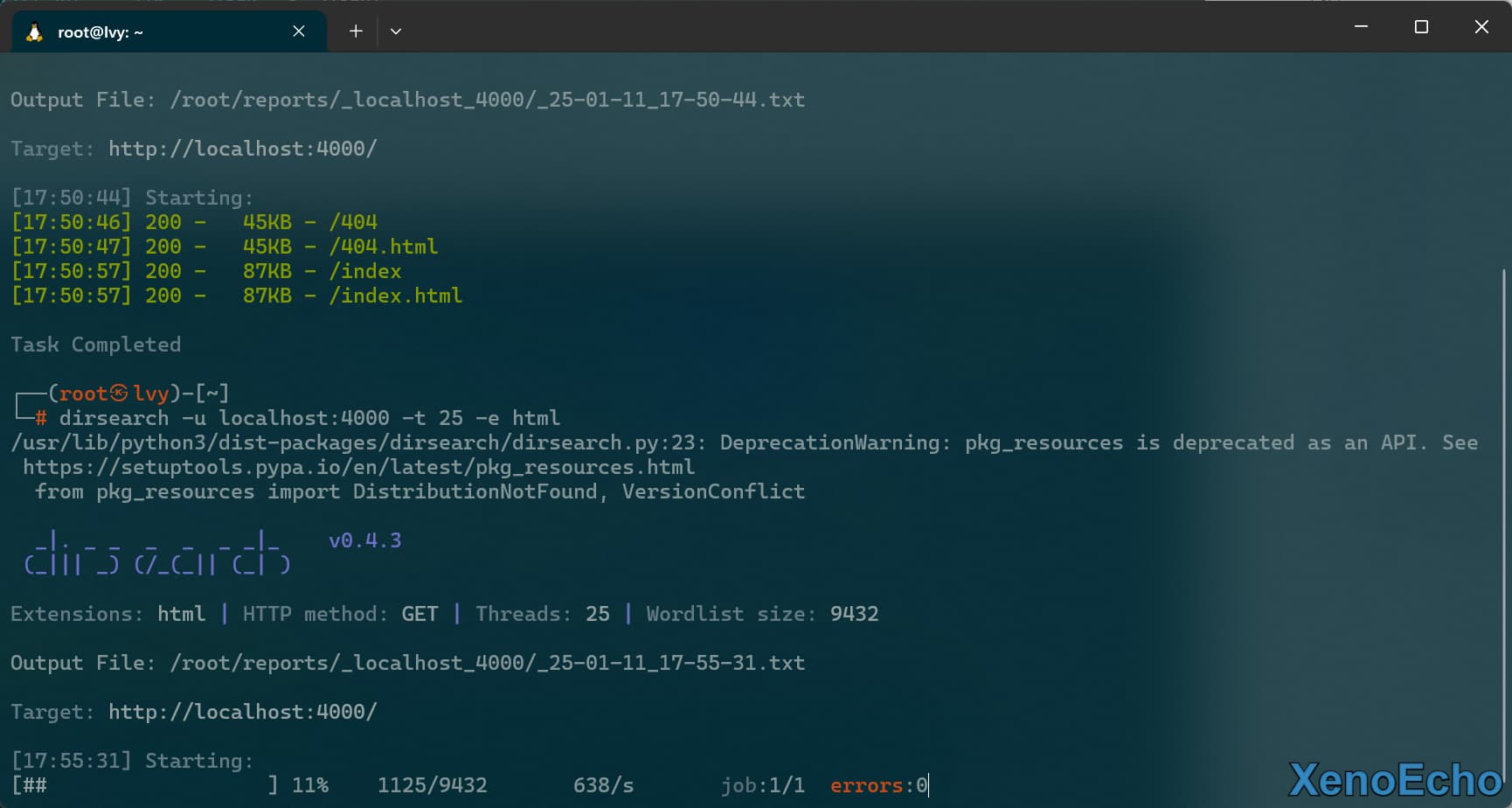
指定扫描格式
- 这个可以根据站点的环境来判断像我我博客是静态部署的。你扫一些
jsp肯说是没有的了。字典一下子少了,原本是一万多的。多个格式的话可以用,分开。
dirsearch -u localhost:4000 -t 25 -e html
|
![Pasted-image-20250111175617]()
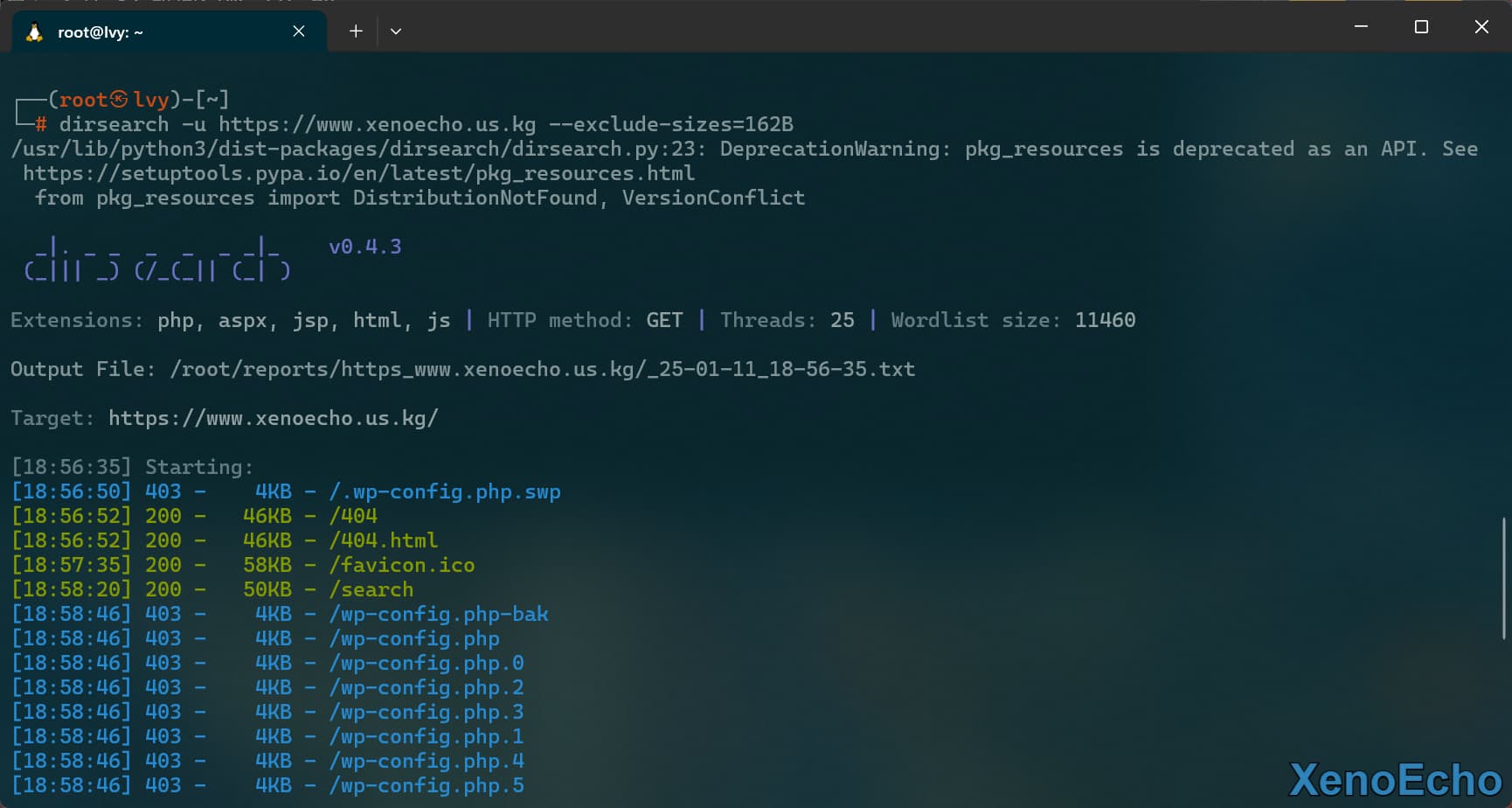
排除响应包大小
- 这个对于真实站点信息收集时有用,部分站点访问一个不存在的页面时会返回一个统一的页面,具体解释看下一级标题详讲解
dirsearch -u https://www.xenoecho.us.kg --exclude-sizes=162B
|
![Pasted-image-20250111185905]()
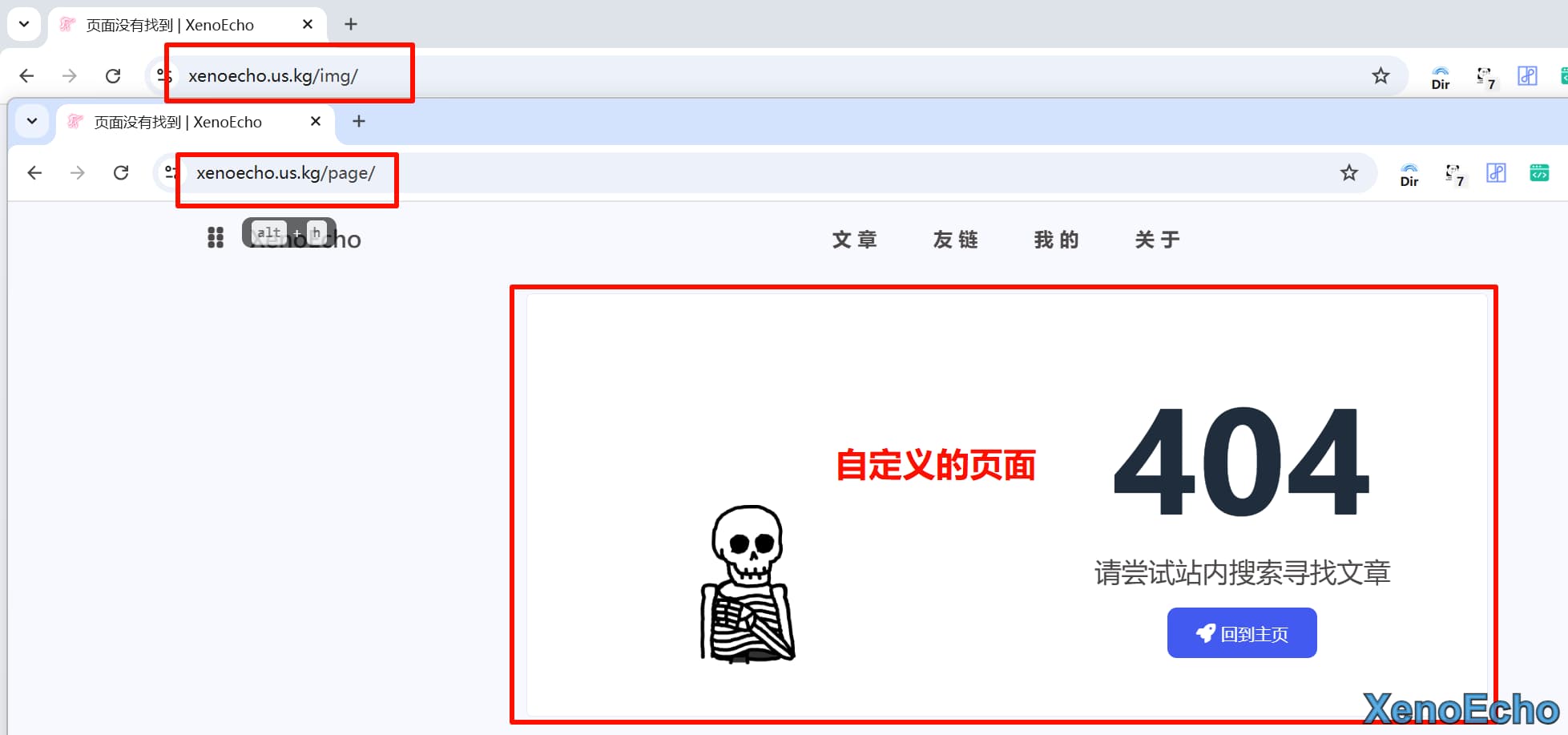
为什么排除
- 注意看我两个不同路径的页面返回的都是我自定义的页面也就是自定义的404
![Pasted-image-20250111183754]()
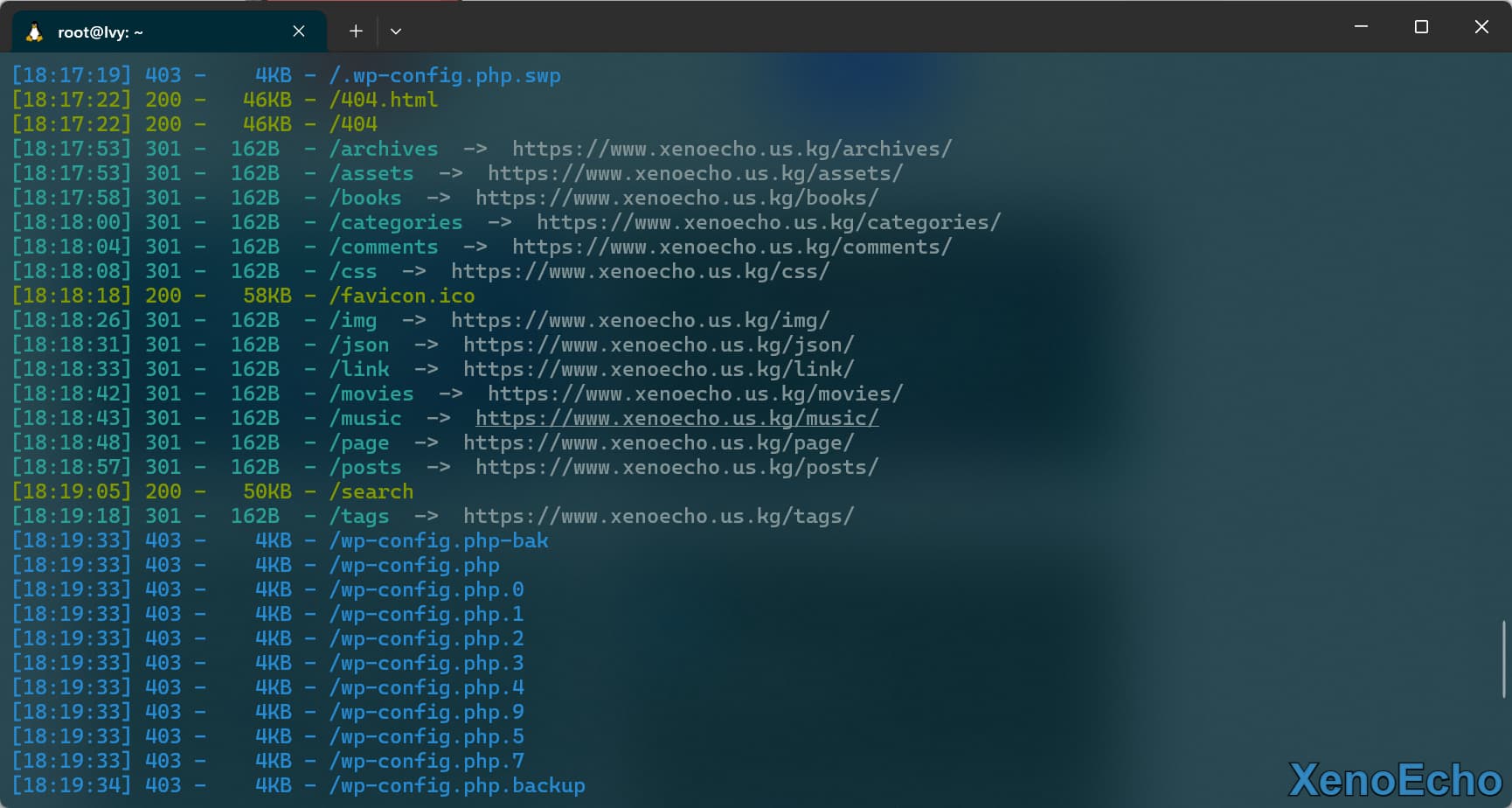
- 而且响应的包大小都是一样,那么就可以使用
--exclude-sizes排除掉这些404页面或者简单的统一页面。
![Pasted-image-20250111182028]()
设置字典
- 目录扫描的本质其实还是信息收集,后续可以根据自己收集到的一些信息制作字典,例如这个网站的文件名为
website,那么可以设置个websaite的名压缩包后缀,或者使用一些常见的字典,如搜索引擎的网站地图、RSS等。
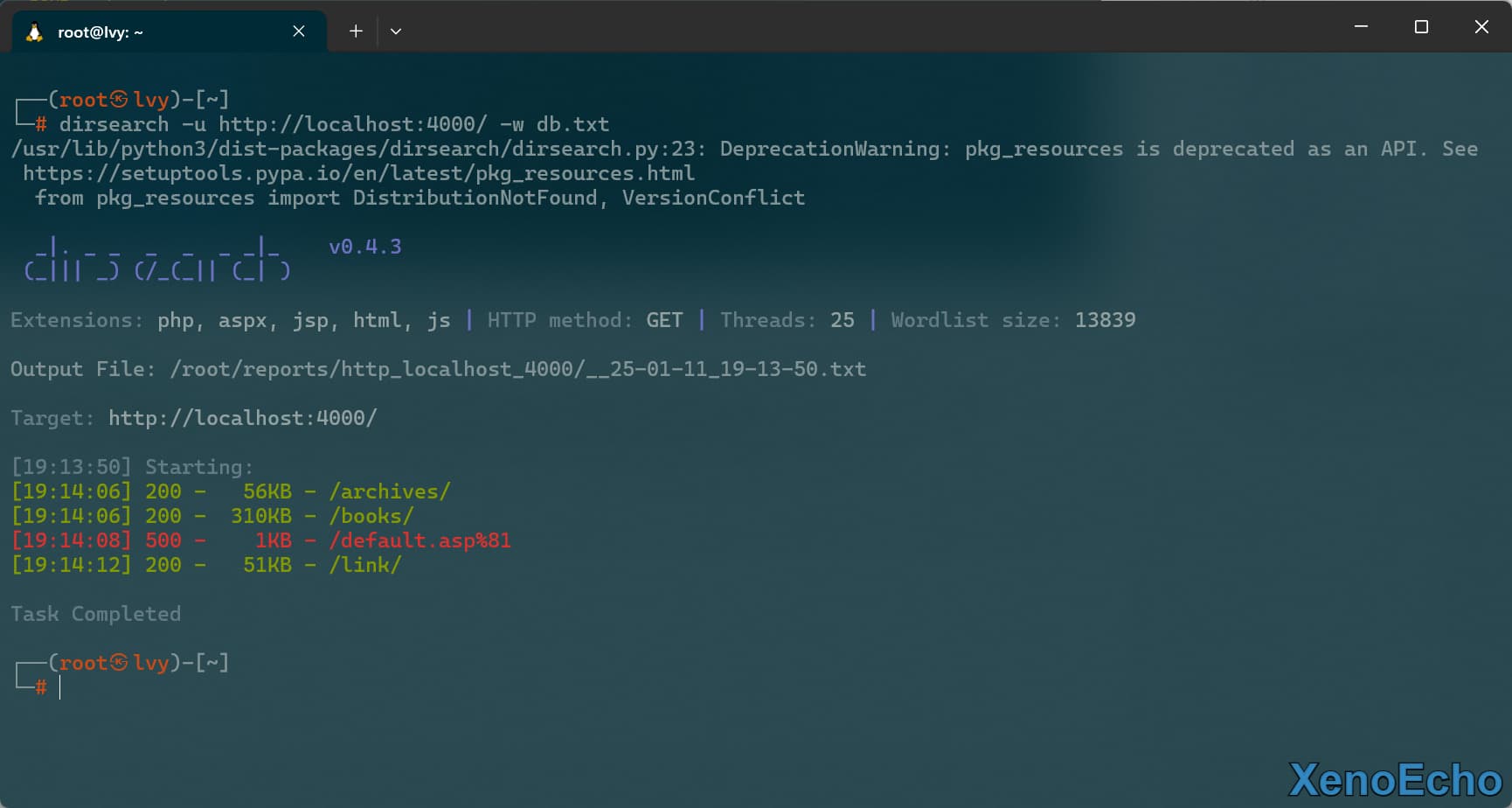
dirsearch -u http://localhost:4000/ -w db.txt
|
![Pasted-image-20250111191428]()
设置代理
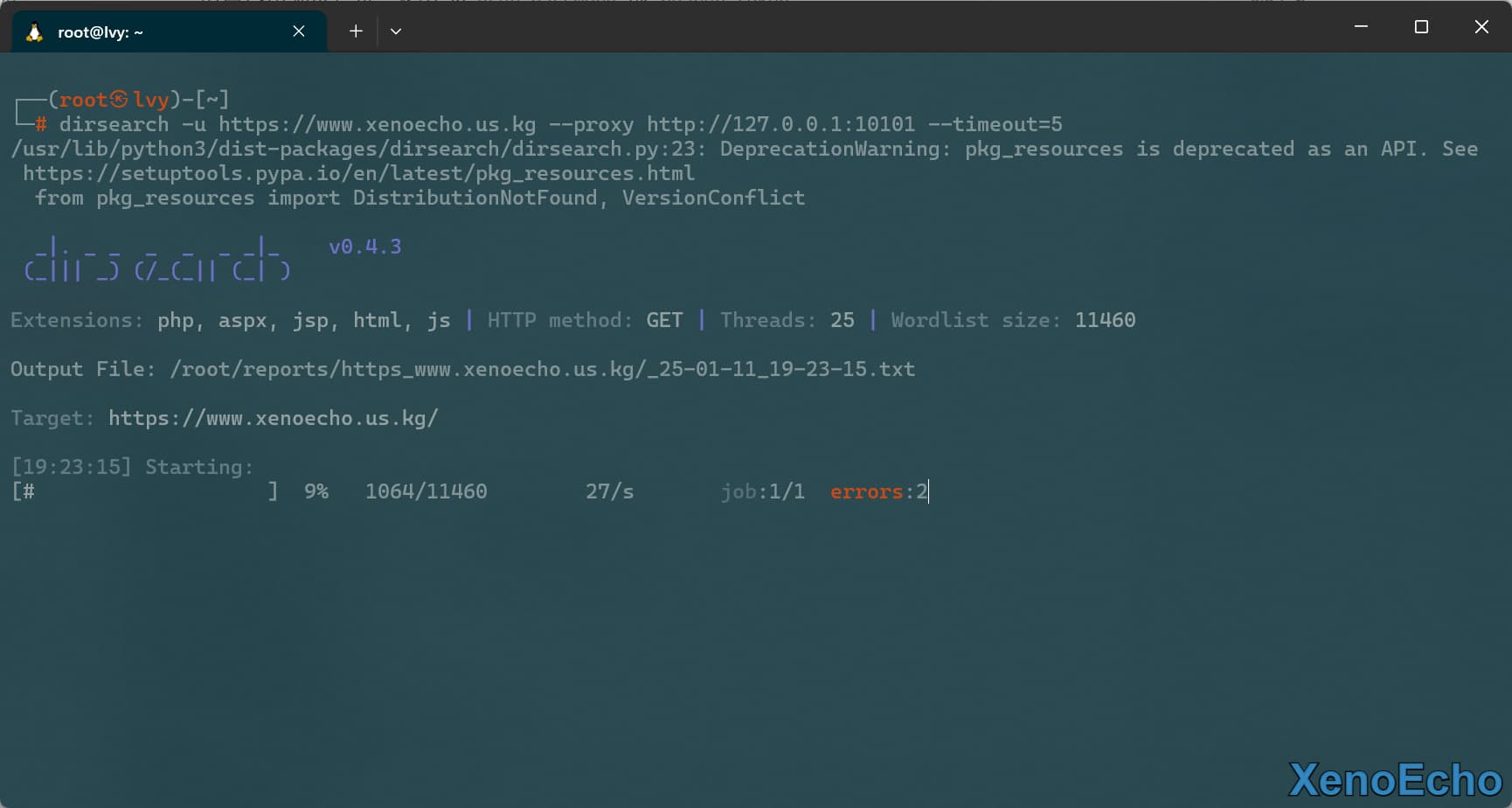
- 这里不代理提供方法,做个示例,
--timeout设置个超时时间。
dirsearch -u https://www.xenoecho.us.kg --proxy http://127.0.0.1:10101 --timeout=5
|
![Pasted-image-20250111192421]()
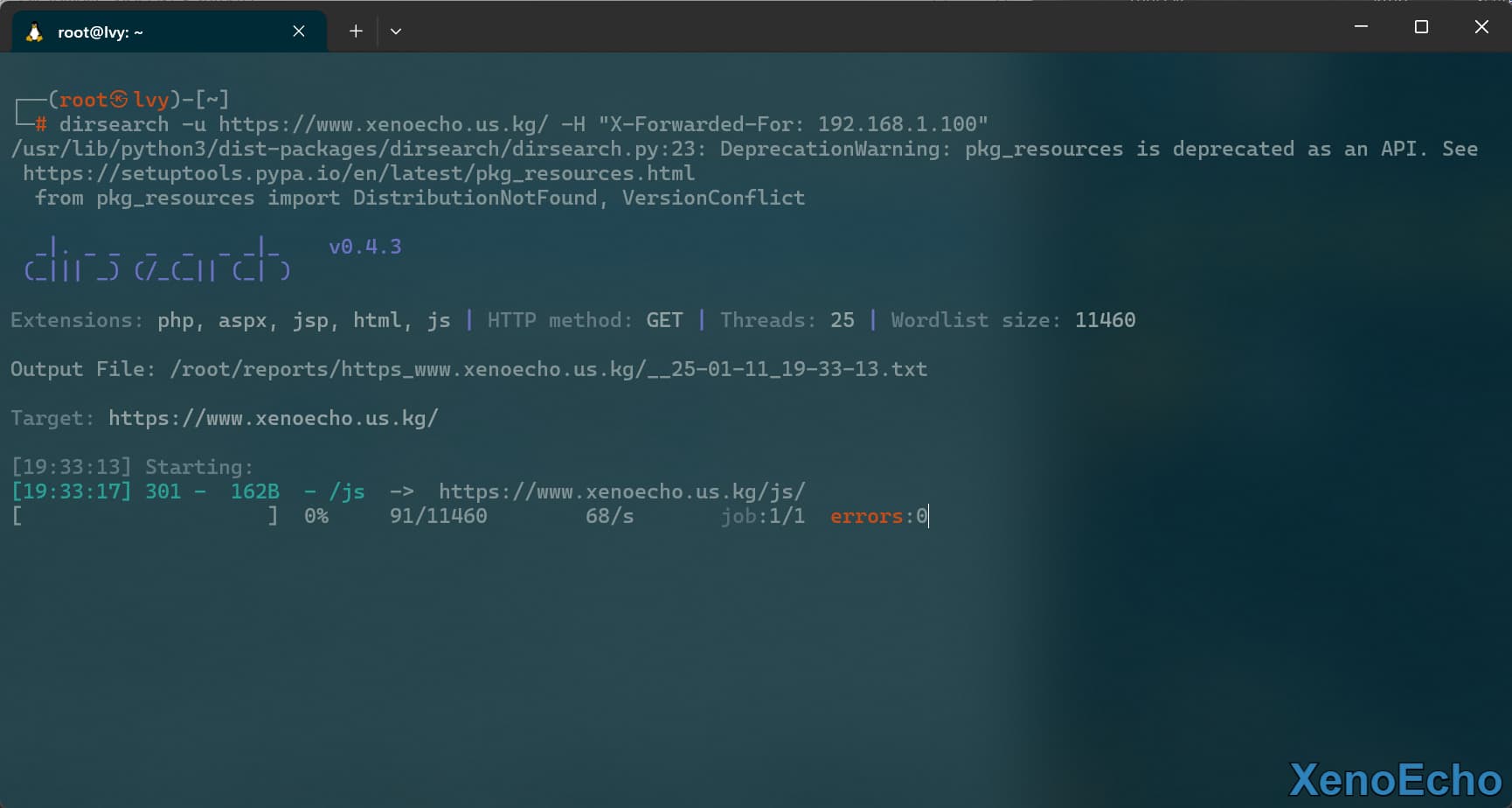
设置请求头| IP伪造
HTTP的请求包中有一个请求头X-Forwarded-For是包含请求IP的,当然这种方式无法欺骗链路层这些,只能欺骗应用层的一些验证。
dirsearch -u https://www.xenoecho.us.kg/ -H "X-Forwarded-For: 192.168.1.100"
|
![Pasted-image-20250111193514]()
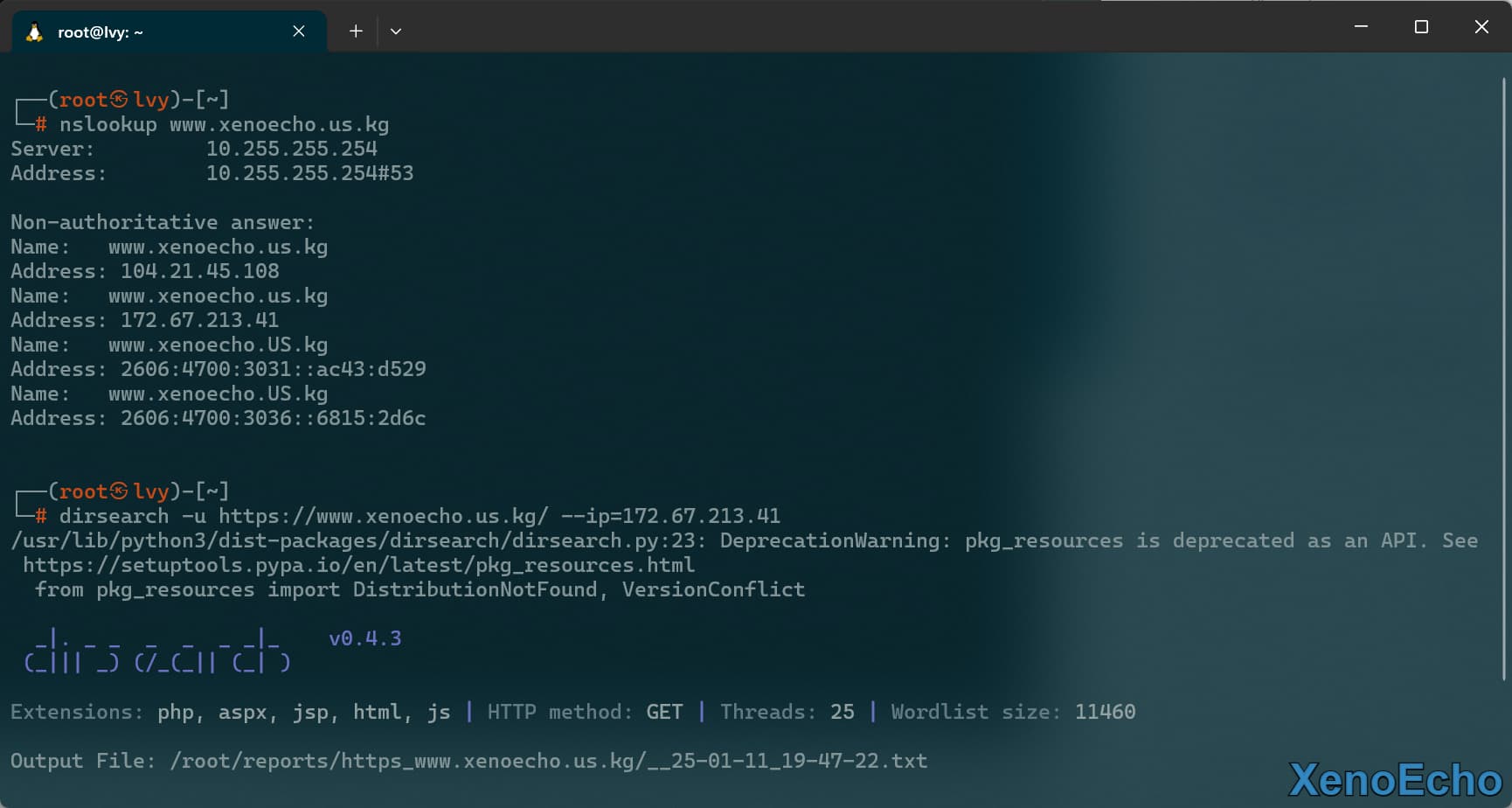
设置IP服务器|绕过CDN请求(存疑)
- 这个参数我感觉很有意思,我可以设置指定的IP请求啊,为什么还要在设置个IP呢,虚拟主机来说也没必要,我感觉大概率可能是针对有
CDN的站点,不过我不确定,这里给个示范。后面有错欢迎指出
dirsearch -u https://www.xenoecho.us.kg/ --ip=172.67.213.41
|
![Pasted-image-20250111194743]()
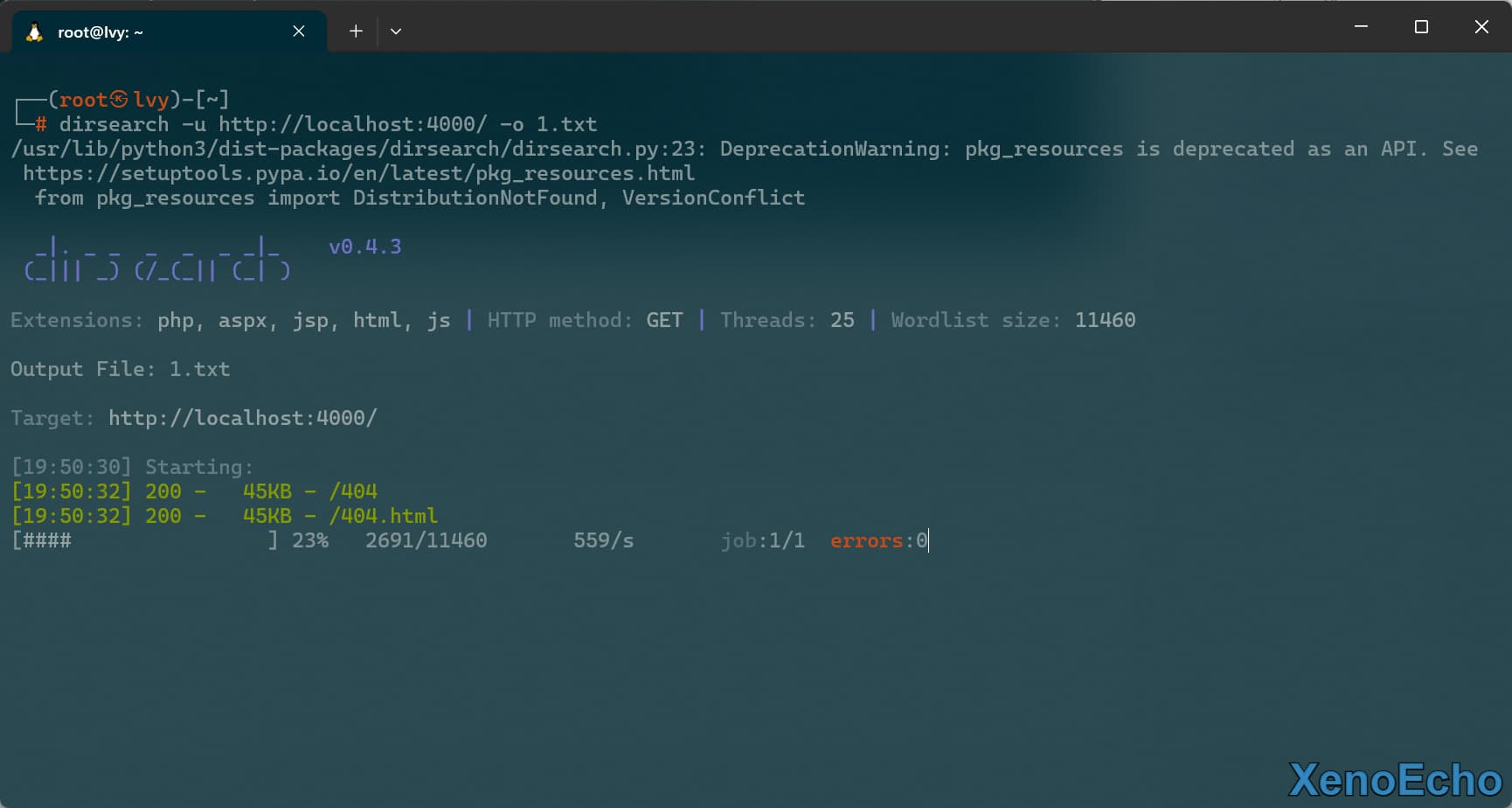
文件另存为
dirsearch -u http://localhost:4000/ -o 1.txt
|
![Pasted-image-20250111195037]()
总结
总体来看Dirsearch已经可以说是很强大的目录扫描工具了,集成大部分扫描中会遇到的所有问题的解决参数,只不过自带的字典肯定不够看的,需要指定字典来完善他的功能。