

Dirb | 目录枚举工具
简介
dirb是 Kali Linux 中一个强大的目录和文件强制枚举工具,用于在 Web 渗透测试中查找隐藏的目录和文件。它通过字典攻击的方式枚举目标网站可能存在的目录和文件,还可以通过检测 HTTP 响应码、响应大小等方式判断哪些路径是有效的。
使用
安装
Dirb基于libcurl开发因此只能通过包管理或者源代码编译安装。windows中需要使用的话可以利用wsl来使用。
包管理器安装
apt install dirb |
Dirb
基本用法
dirb <目标URL> [字典文件] [选项] |
命令参数
| 参数 | 说明 | 示例使用 |
|---|---|---|
-a <agent_string> |
自定义用户代理字符串 (User-Agent),用于模拟特定浏览器或绕过简单的反爬虫措施 | dirb http://example.com/ -a "Mozilla/5.0" |
-b |
使用原始路径,不做任何附加处理(不会自动加/) |
dirb http://example.com/ -b |
-c <cookie_string> |
设置 HTTP 请求中的 Cookie 信息 | dirb http://example.com/ -c "sessionid=abcd1234" |
-E <certificate> |
使用客户端证书进行请求,适用于 SSL/TLS 认证 | dirb https://example.com/ -E /path/to/cert.pem |
-f |
调优 404 错误的检测方式 | dirb http://example.com/ -f |
-H <header_string> |
添加自定义的 HTTP 请求头,例如 Referer、Authorization | dirb http://example.com/ -H "Referer: http://example.com/home" |
-i |
进行大小写不敏感的路径搜索 | dirb http://example.com/ -i |
-l |
显示响应中的 Location 头部,通常用于处理重定向 | dirb http://example.com/ -l |
-N <nf_code> |
忽略指定的 HTTP 响应码,通常用于忽略 404(未找到)等不需要处理的响应 | dirb http://example.com/ -N 404 |
-o <output_file> |
将扫描结果输出到指定文件 | dirb http://example.com/ -o results.txt |
-p <proxy[:port]> |
通过指定的代理服务器进行扫描,默认代理端口是 1080 | dirb http://example.com/ -p 127.0.0.1:8080 |
-P <proxy_username:proxy_password> |
配置代理服务器的认证信息 | dirb http://example.com/ -P "user:pass" |
-r |
不进行递归扫描,只扫描指定的路径 | dirb http://example.com/ -r |
-R |
交互式递归扫描,会询问是否扫描子目录 | dirb http://example.com/ -R |
-S |
静默模式,不显示测试的路径,只显示结果 | dirb http://example.com/ -S |
-t |
不自动在路径末尾添加/,适用于没有目录结构的情况 |
dirb http://example.com/ -t |
-u <username:password> |
使用 HTTP 基本认证(用户名:密码)进行身份验证 | dirb http://example.com/ -u "user:password" |
-v |
显示 404 页面,默认情况下不显示 404 响应页面 | dirb http://example.com/ -v |
-w |
扫描过程中不会因警告信息而停止 | dirb http://example.com/ -w |
-X <extensions> / -x <exts_file> |
在每个字典单词后面附加文件扩展名(如.php、.html)进行测试 |
dirb http://example.com/ -X .html,.php |
-z <millisecs> |
在请求之间添加毫秒级延迟,避免请求过快触发目标的防护机制 | dirb http://example.com/ -z 500 |
使用站点
- 这里使用的为前面的Kioptrix-Level靶机
![Pasted-image-20250113162249]()
默认扫描
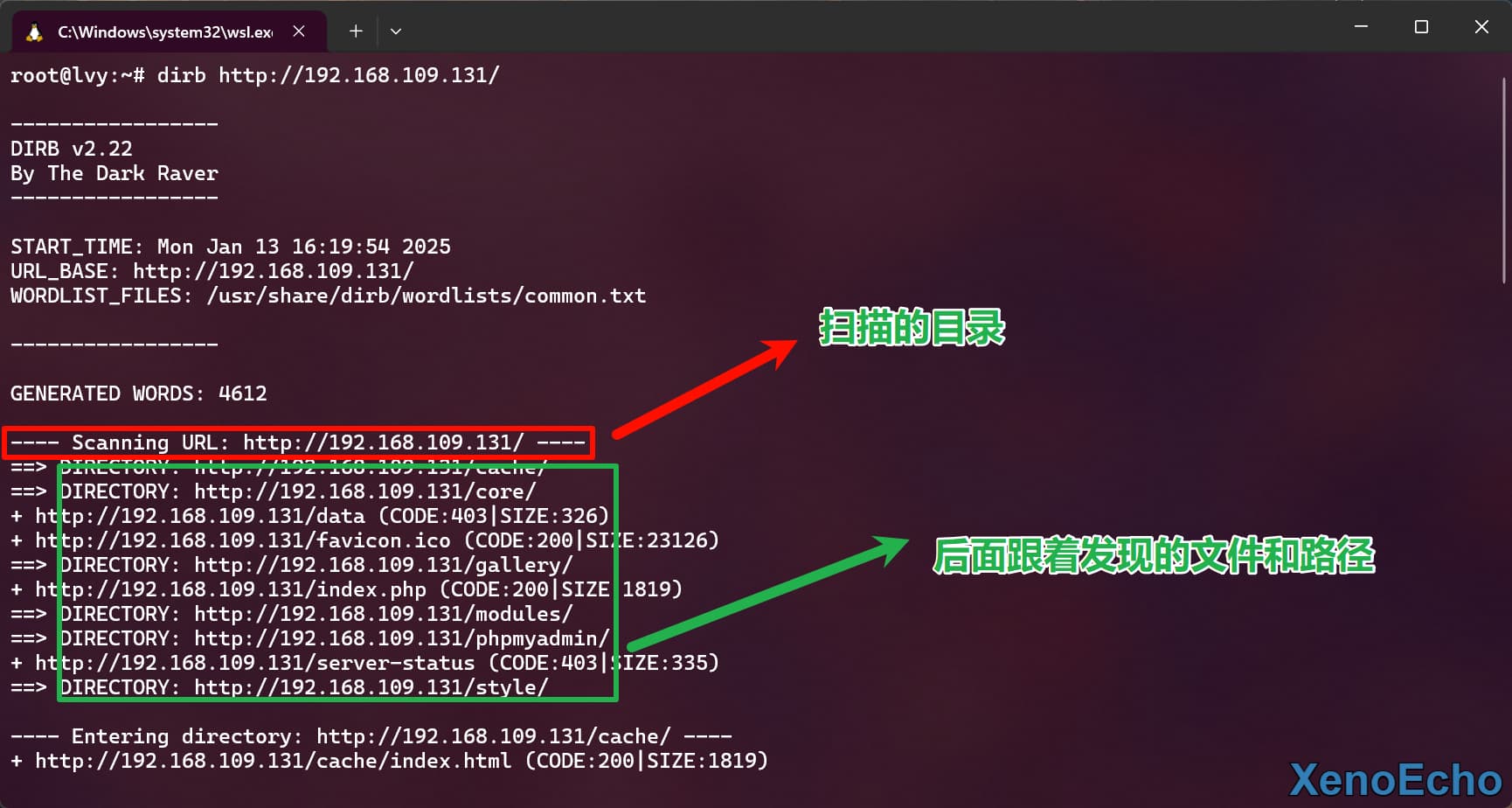
- 默认扫描会在指定的
url的路径进行扫描,不指定字典则使用common.txt字典,并默认开启递归。可以带上-w无视警告扫描。
dirb http://192.168.109.131/ |
扫描路径
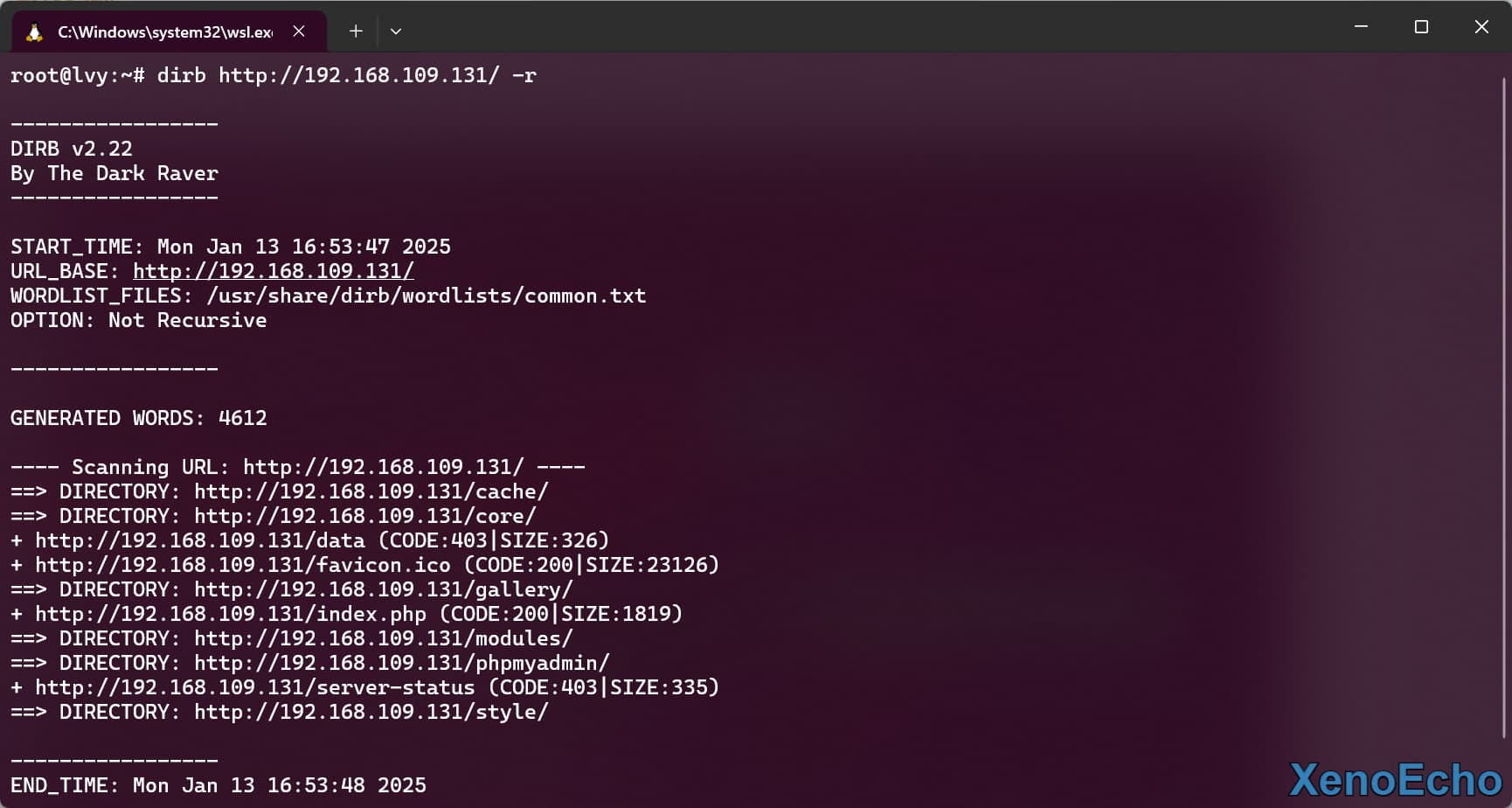
- 使用
-r参数关闭递归扫描
dirb http://192.168.109.131/ -r |
设置用户代理
- 使用
-a参数来模拟用户来进行扫描。不过记得很少站点限制用户代理的。
dirb http://192.168.109.131/ -a "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36" |
自定义字典扫描
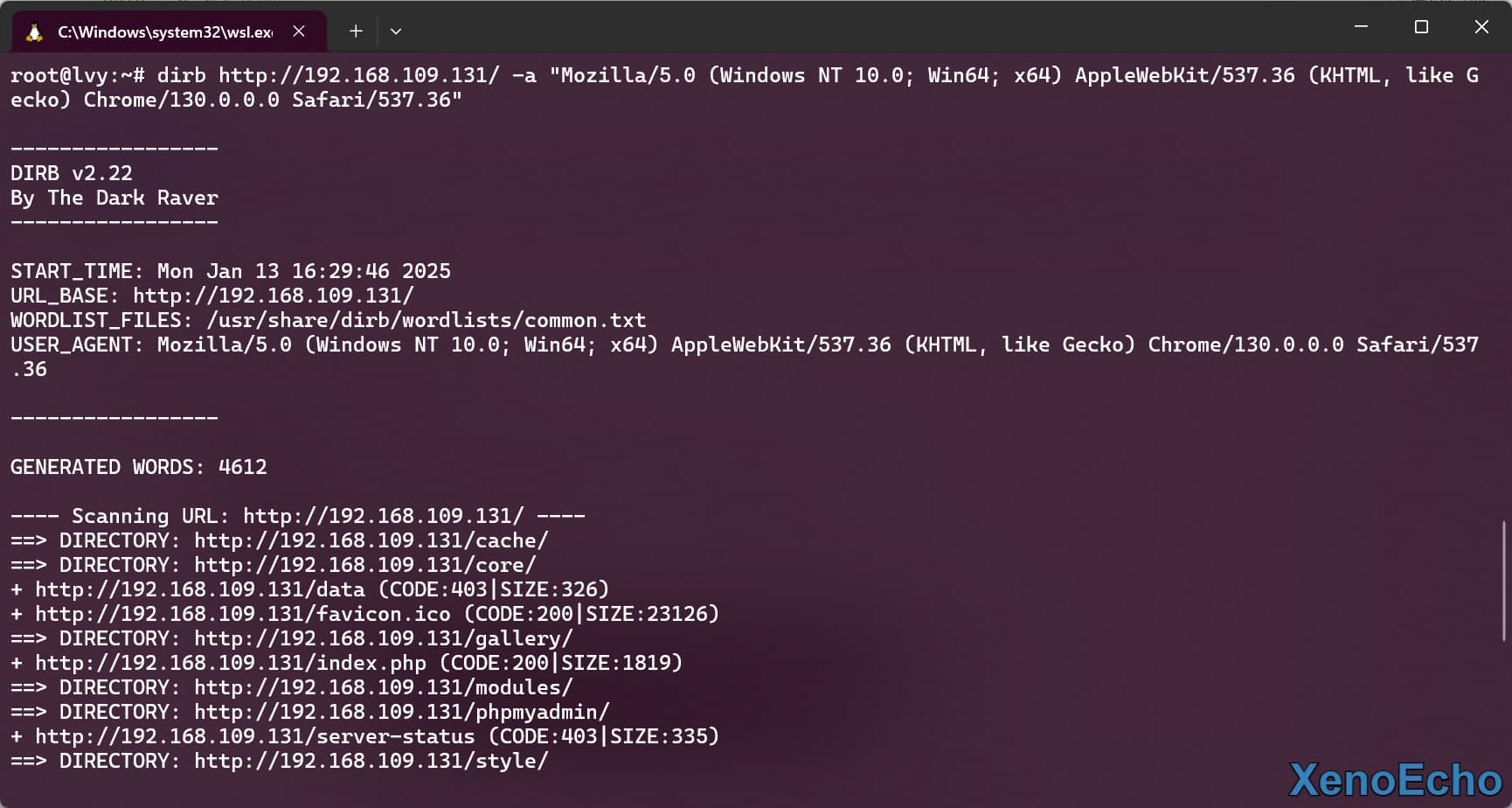
Dirb的自带字典路径在/usr/share/dirb/wordlists/,当然也可以使用之前Dirsearch的字典或者自定义字典
dirb http://192.168.109.131/ /usr/share/dirb/wordlists/small.txt |
扫描指定扩展
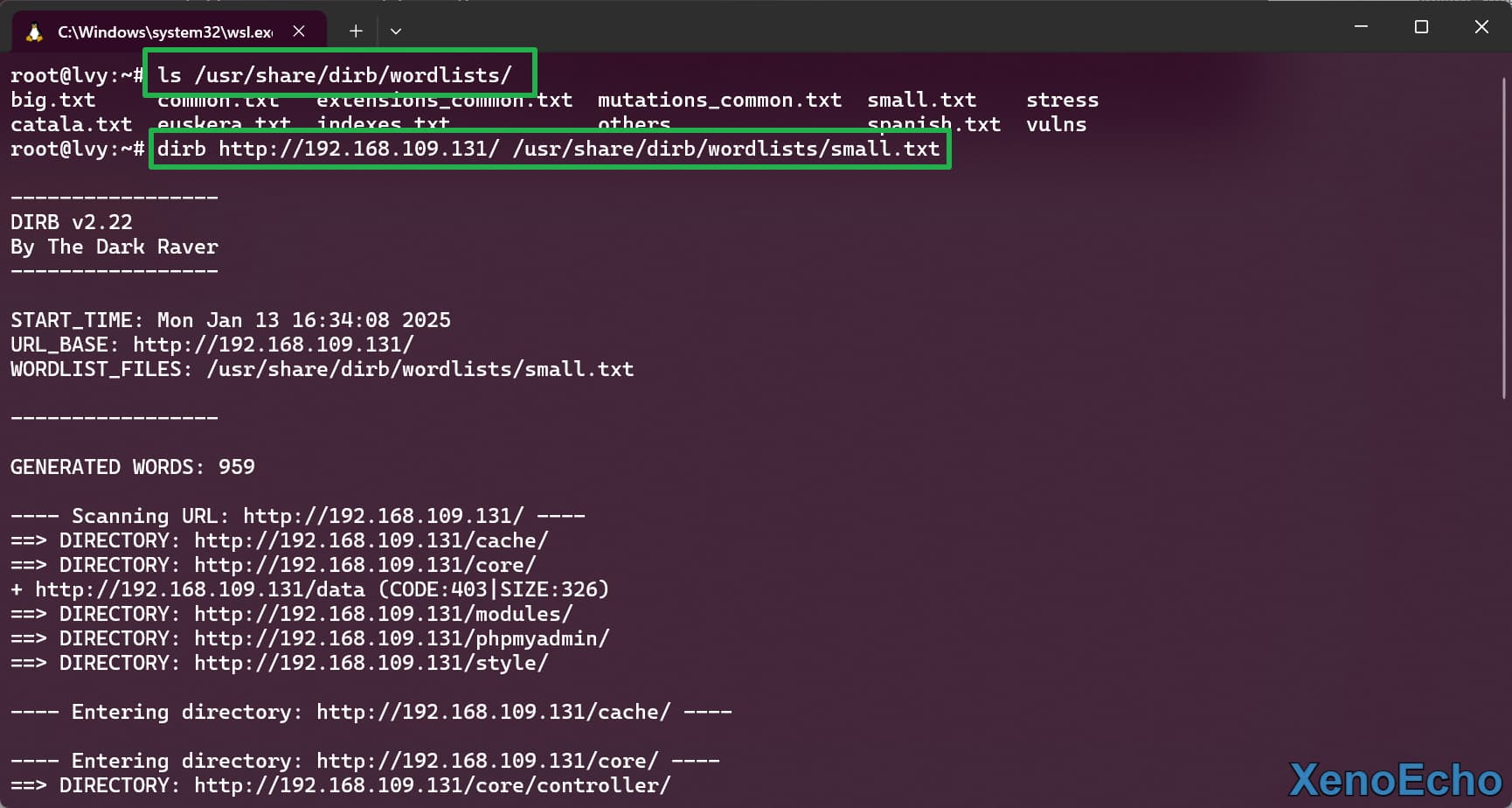
- 可以对站点的环境信息进行信息收集,来扫描指定的环境文件或者一些备份和敏感文件。(在指定的字典后面添加扩展名)多个扩展名用
,分隔。
dirb http://192.168.109.131/gallery/ -X .sql |
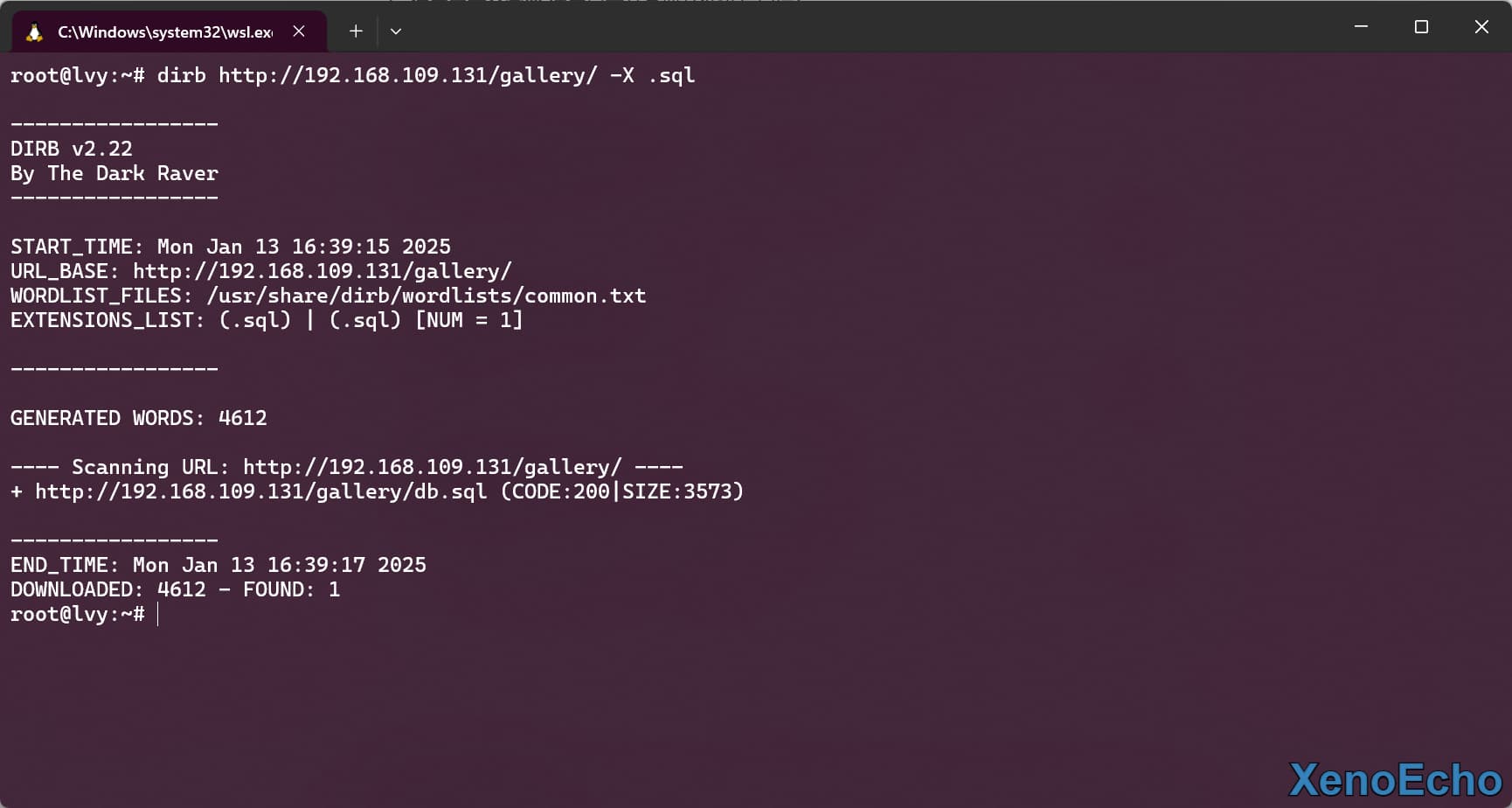
使用代理扫描
- 代理方式很多,不提供方法,举个例子。使用的为
http代理
dirb https://www.xenoecho.us.kg/ -p 127.0.0.1:10101 |
排除状态码
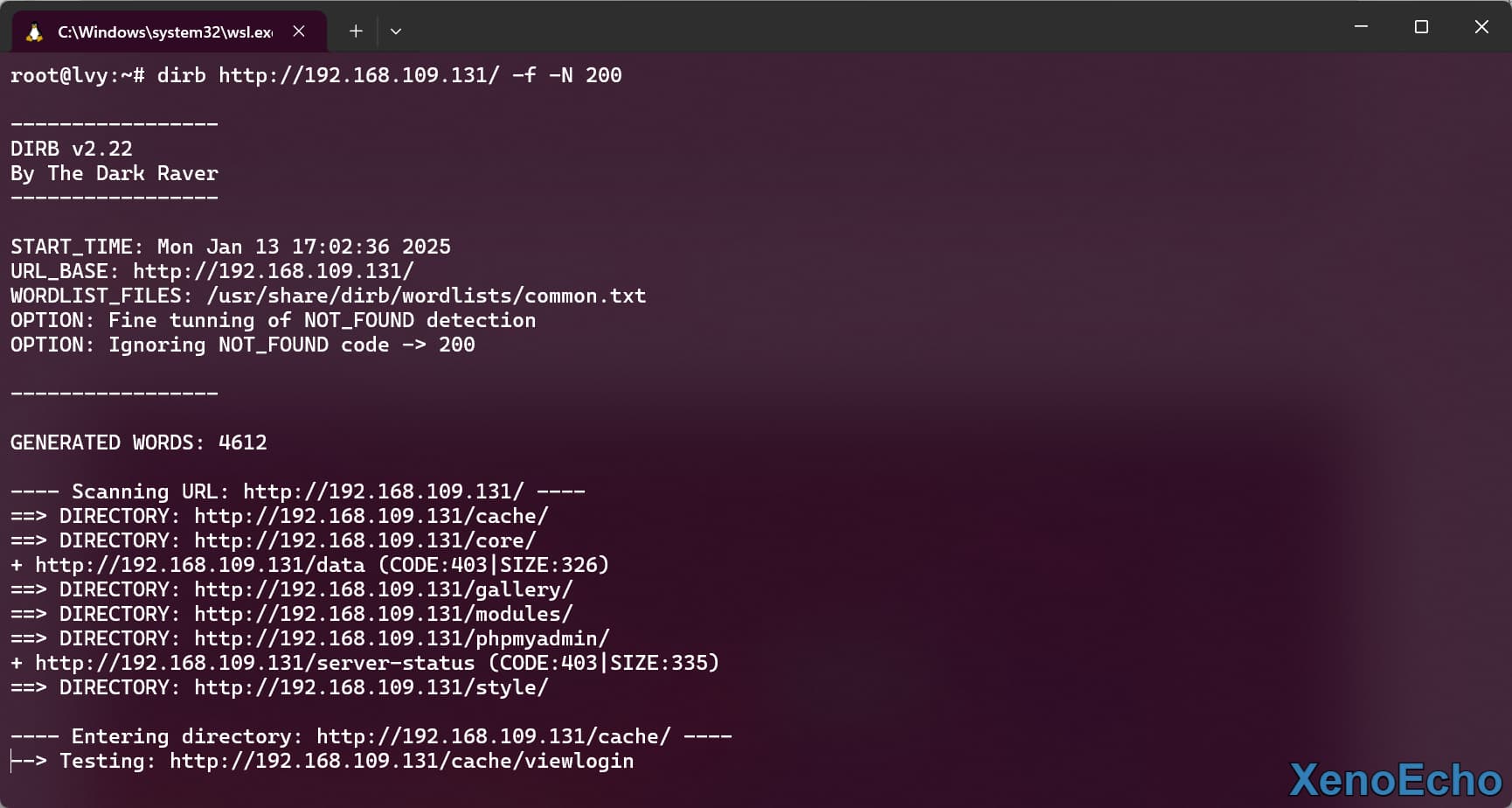
-f优化404检错方式,-N排除指定状态码。因为404是默认排除的所以排除200,排除多个可用多个-N
dirb http://192.168.109.131/ -f -N 200 |
自定义请求头
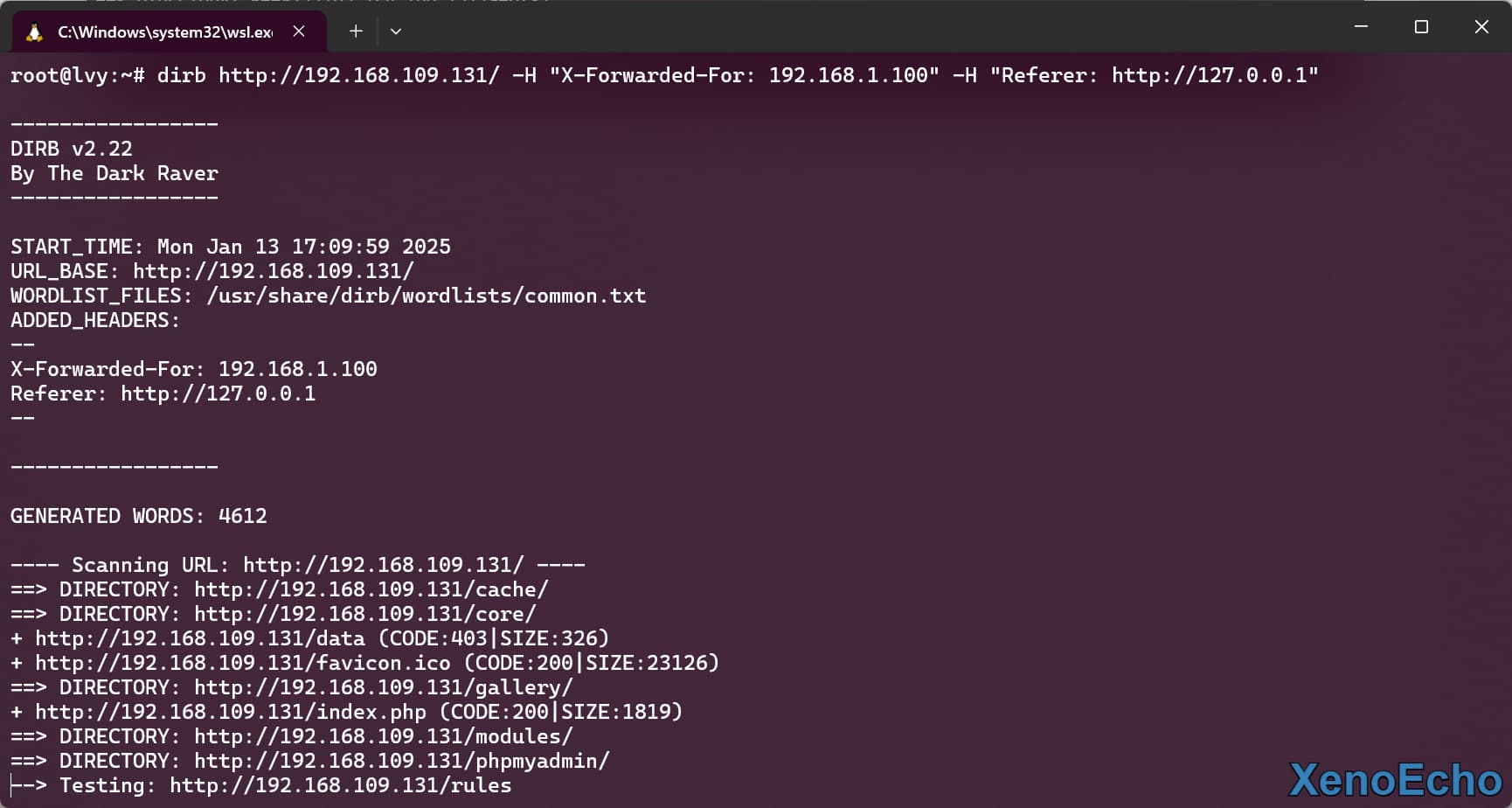
- 使用
-H参数来设置多个请求头,设置多个可用多个-H
dirb http://192.168.109.131/ -H "X-Forwarded-For: 192.168.1.100" -H "Referer: http://127.0.0.1" |
将结果保存
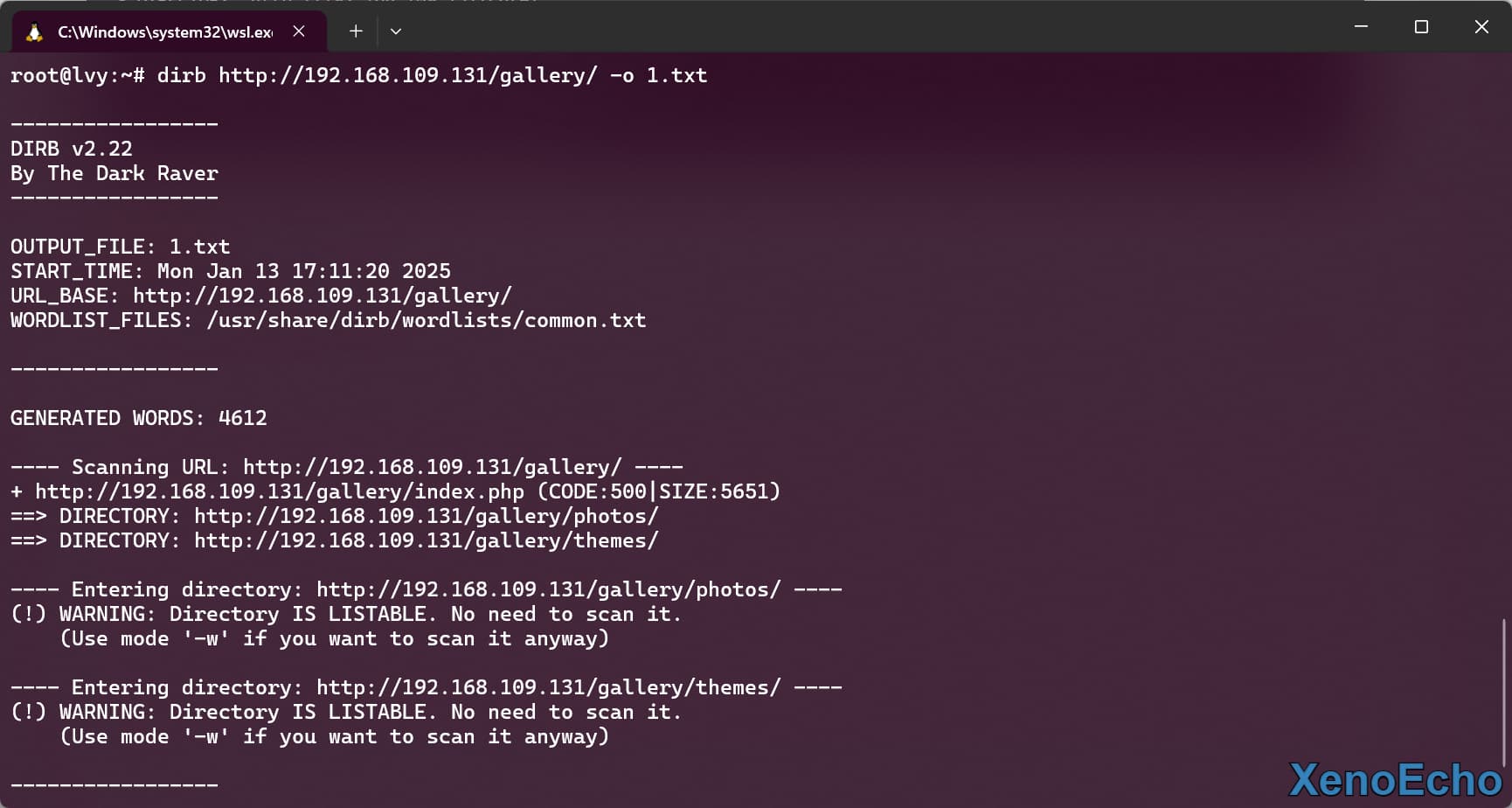
- 使用
-o设置保存的文件名,默认是不回显的。
dirb http://192.168.109.131/gallery/ -o 1.txt |
dirb-gendict
dirb-gendict是dirb包里面自带的一个灵活的字典生成工具,通过使用模式字符串和字符类型,可以快速生成符合特定需求的自定义字典。例如,在渗透测试中生成用户列表、路径列表或密码列表时非常有用。
基本用法
dirb-gendict <wordlist_file> [options] |
命令参数
| 参数 | 描述 | 范围 |
|---|---|---|
-n |
生成数字序列 | 0-9 |
-c |
生成小写字母序列 | a-z |
-C |
生成大写字母序列 | A-Z |
-h |
生成十六进制序列 | 0-f |
-a |
生成字母数字混合序列 | 0-9a-z |
-s |
生成大小写敏感的字母数字混合序列 | 0-9a-zA-Z |
wordlist_file |
ASCII 字符串,其中每个X 将被对应的递增值替换 |
字符串,包含X |
生成例子
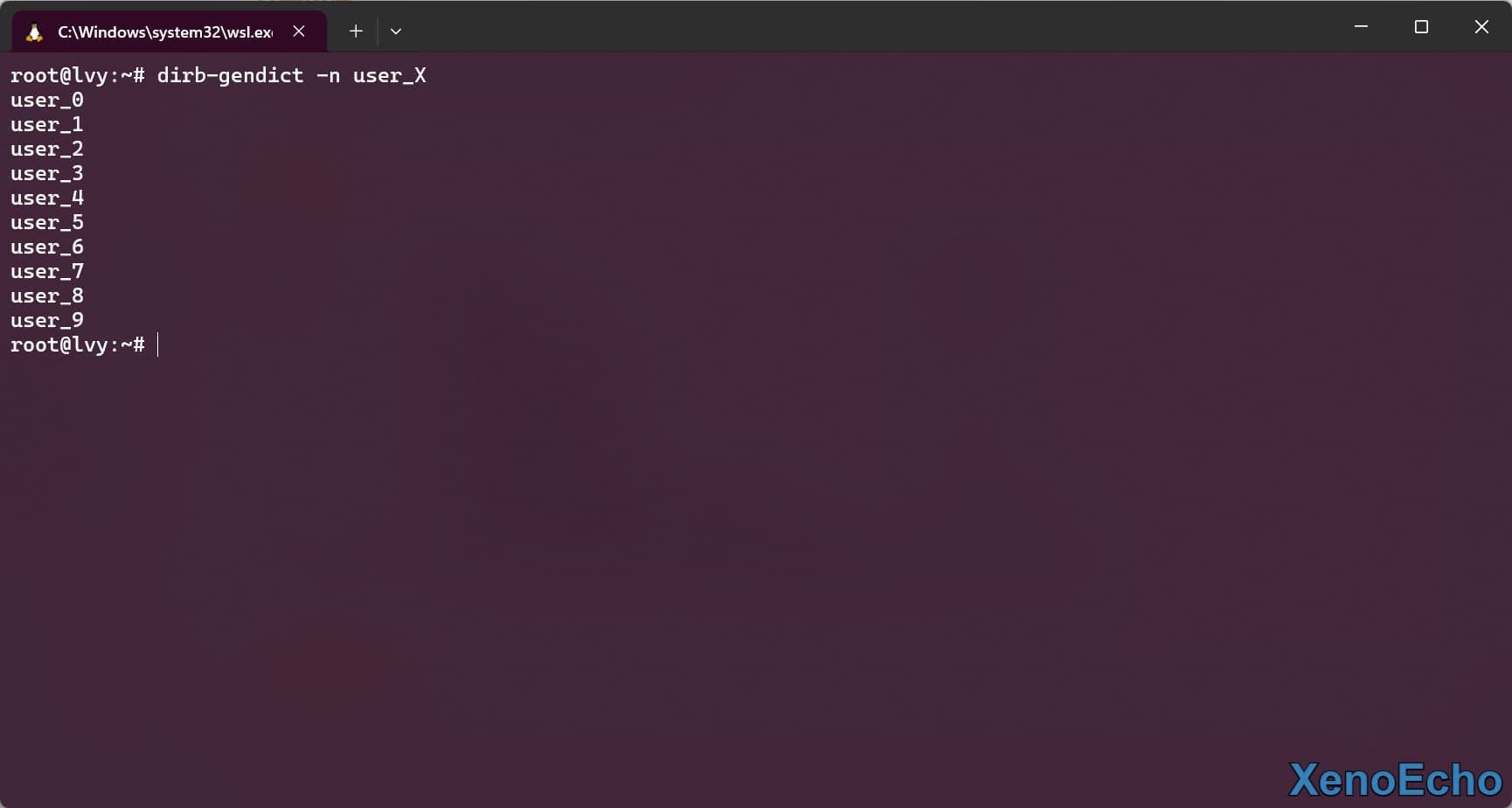
- 使用对应的参数来生成对应序列字符
dirb-gendict -n user_X |
保存生成
- 使用重定向符到文件
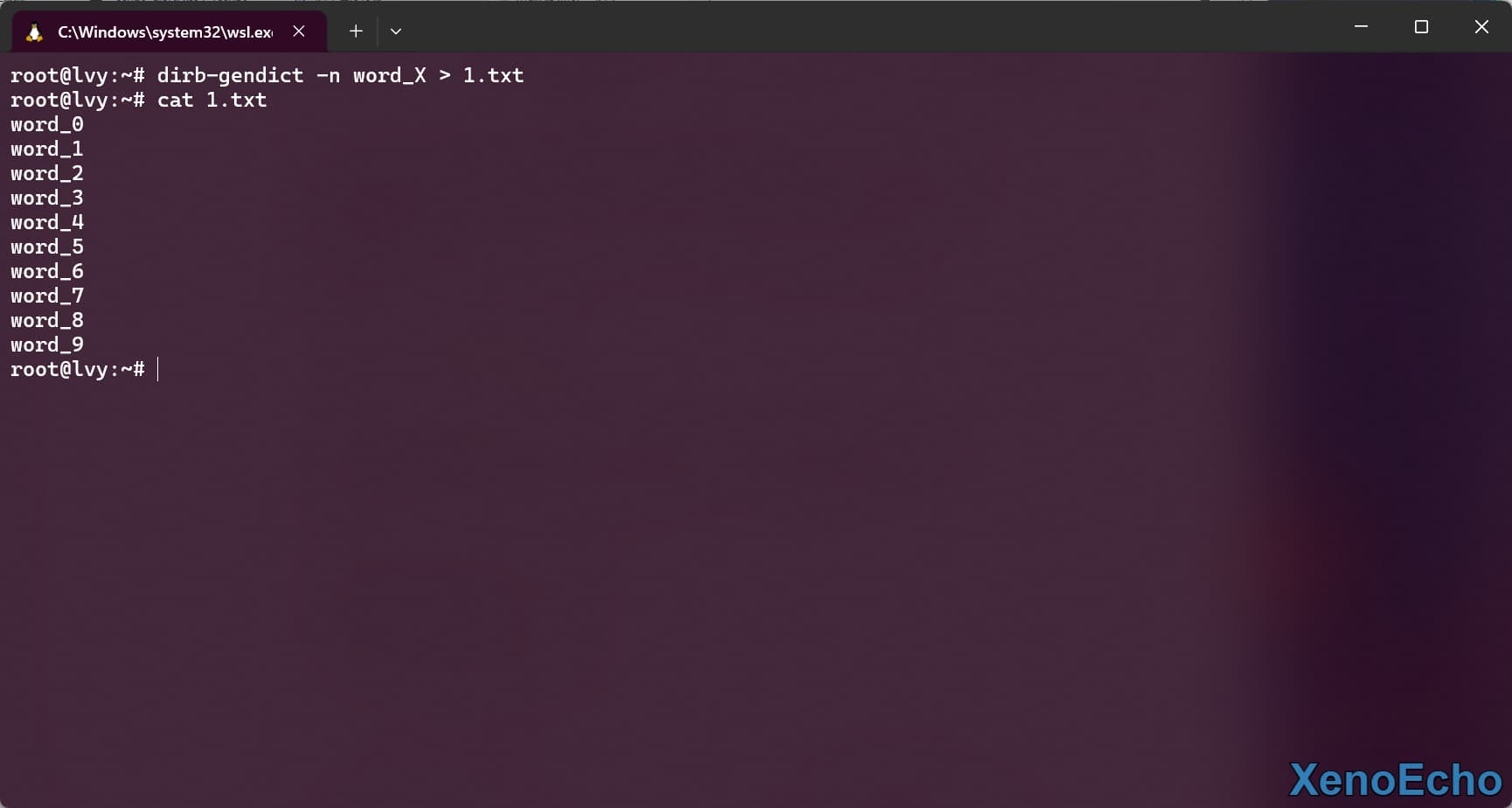
dirb-gendict -n word_X > 1.txt |
html2dic
html2dic通过html文件输入,从 HTML 页面中提取单词并生成字典文件的命令行工具,从HTML 页面中的所有单词提取出来,并将每个单词按行列出,最终生成一个字典,输出结果会打印到标准输出
基本用法
- 直接输入网页文件即可,无任何参数
html2dic <file> |
获取页面
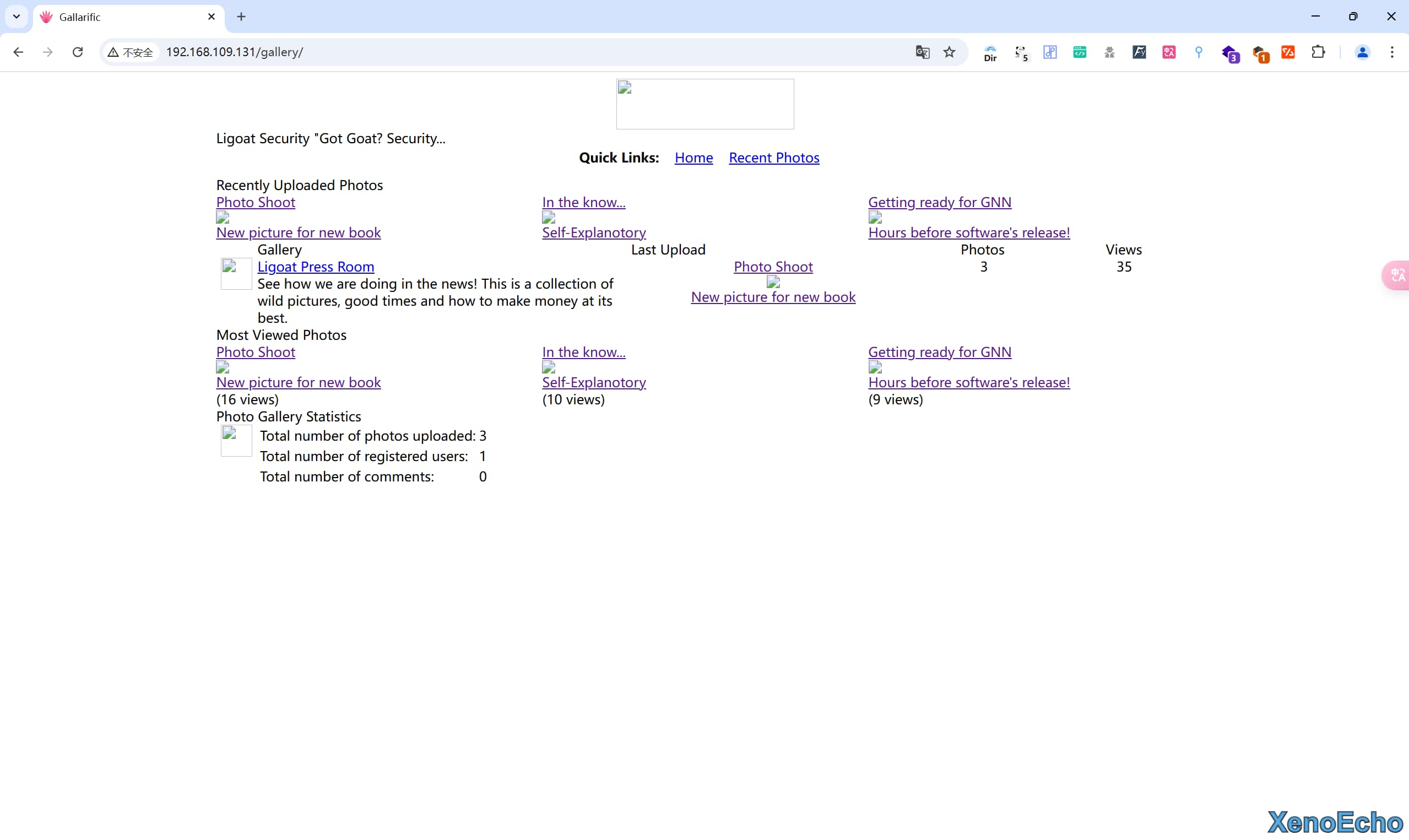
- 爬取的页面
![Pasted-image-20250113230458]()
获取网页文件
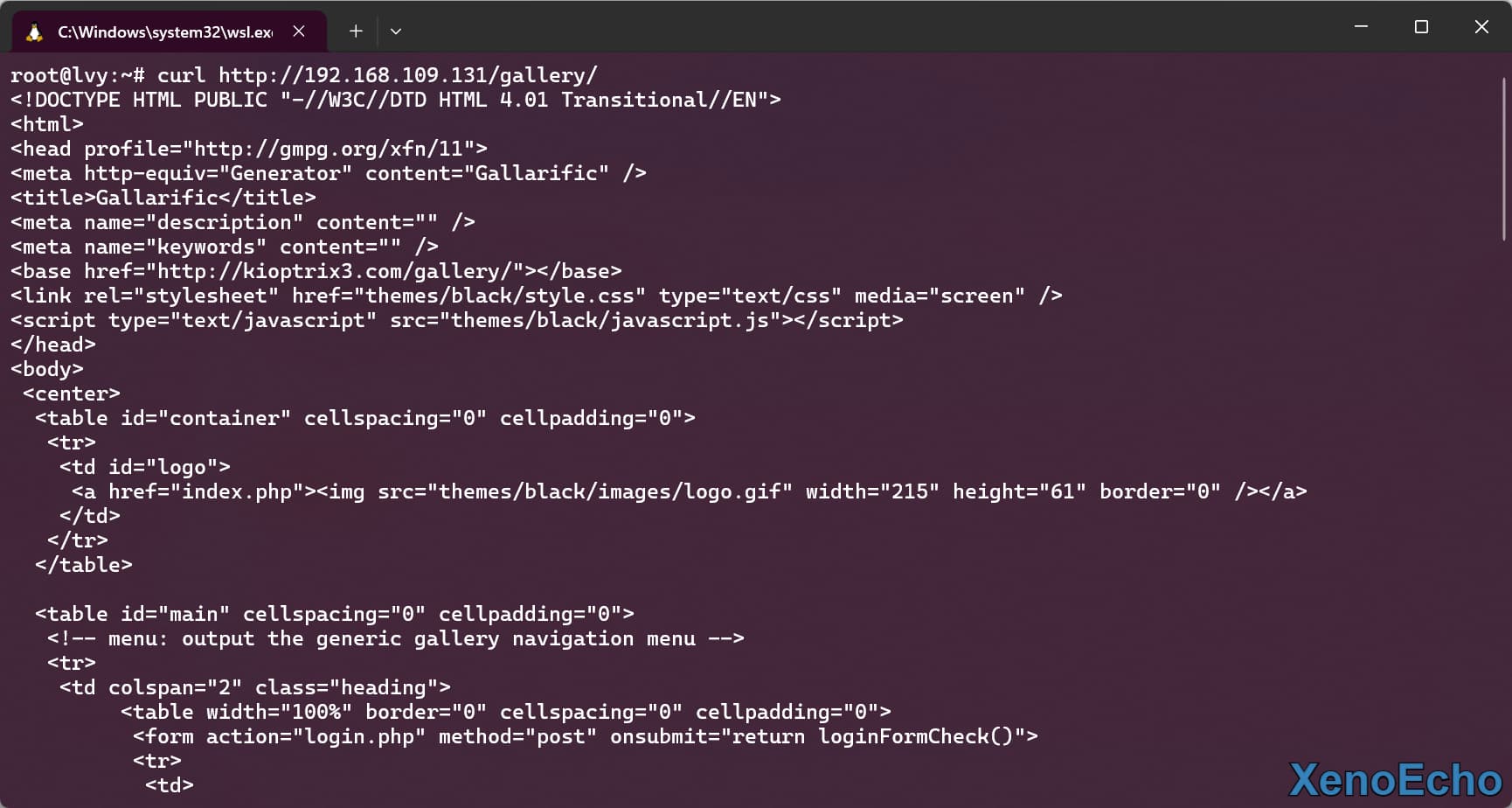
- 首先知道
Curl命令可以对页面发送请求![Pasted-image-20250113230431]()
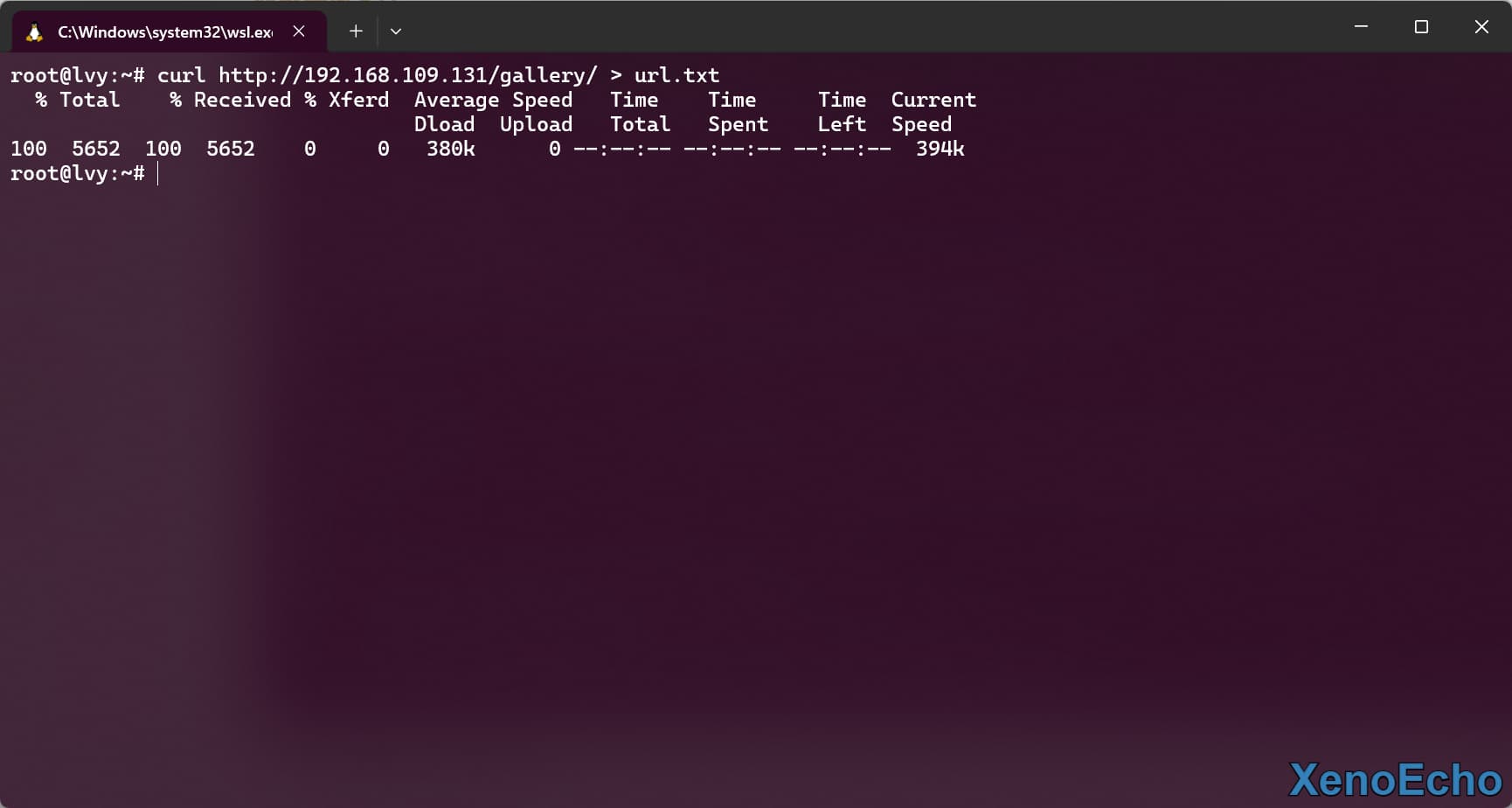
- 然后利用重定向保存起来
curl http://192.168.109.131/gallery/ > url.txt |
- 然后利用命令爬取,重定向保存为字典就不示范了。
html2dic url.txt |
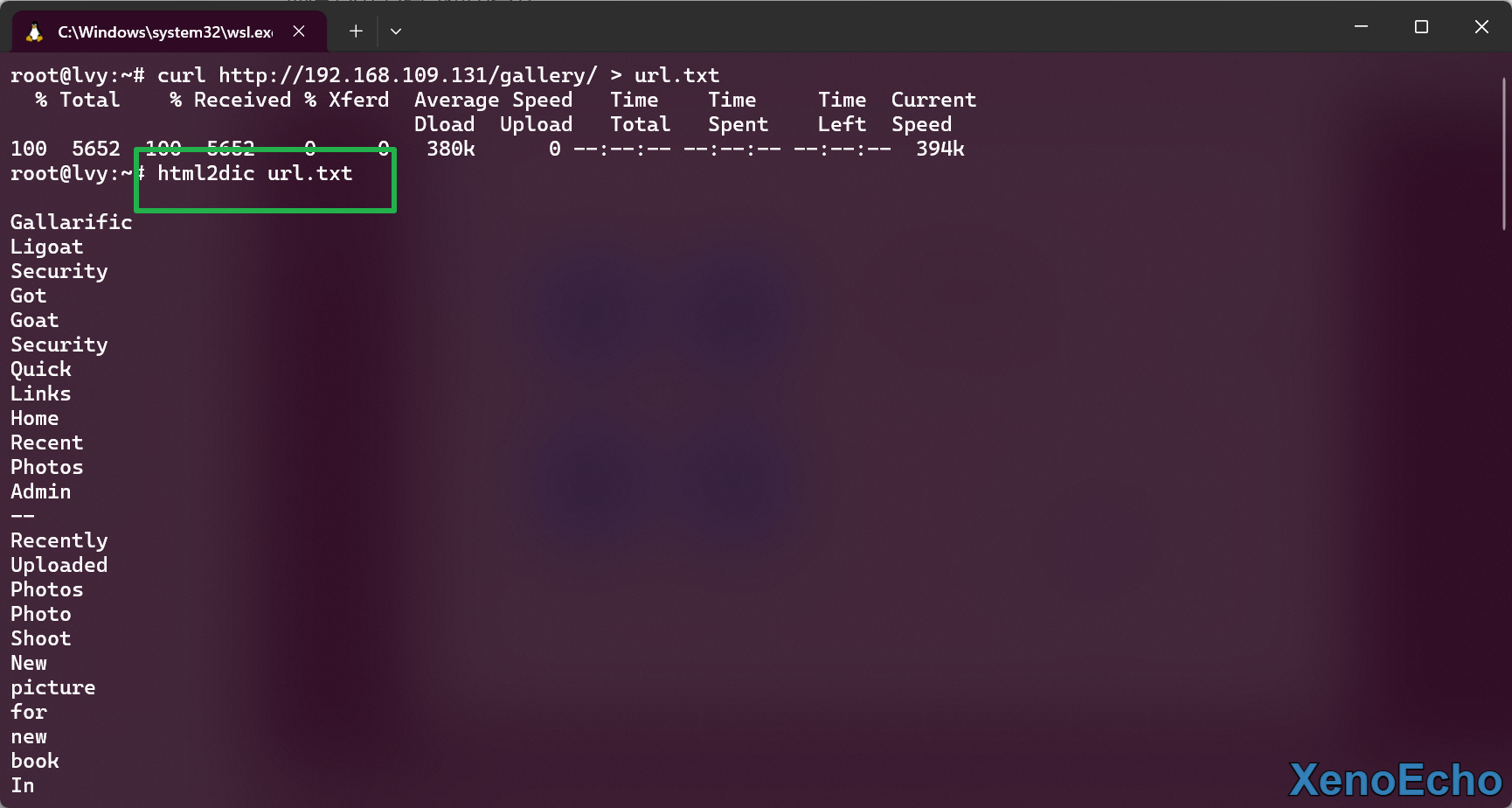
缺点
- 这个缺点很致命,这里拿我博客进行测试。可以看到页面都看得懂(大部分中文)
![Pasted-image-20250113231810]()
- 爬取页面并抓取,发现这玩也不能搞中文,真和他描述的一模一样,面对中文站点直接out
![Pasted-image-20250113232111]()
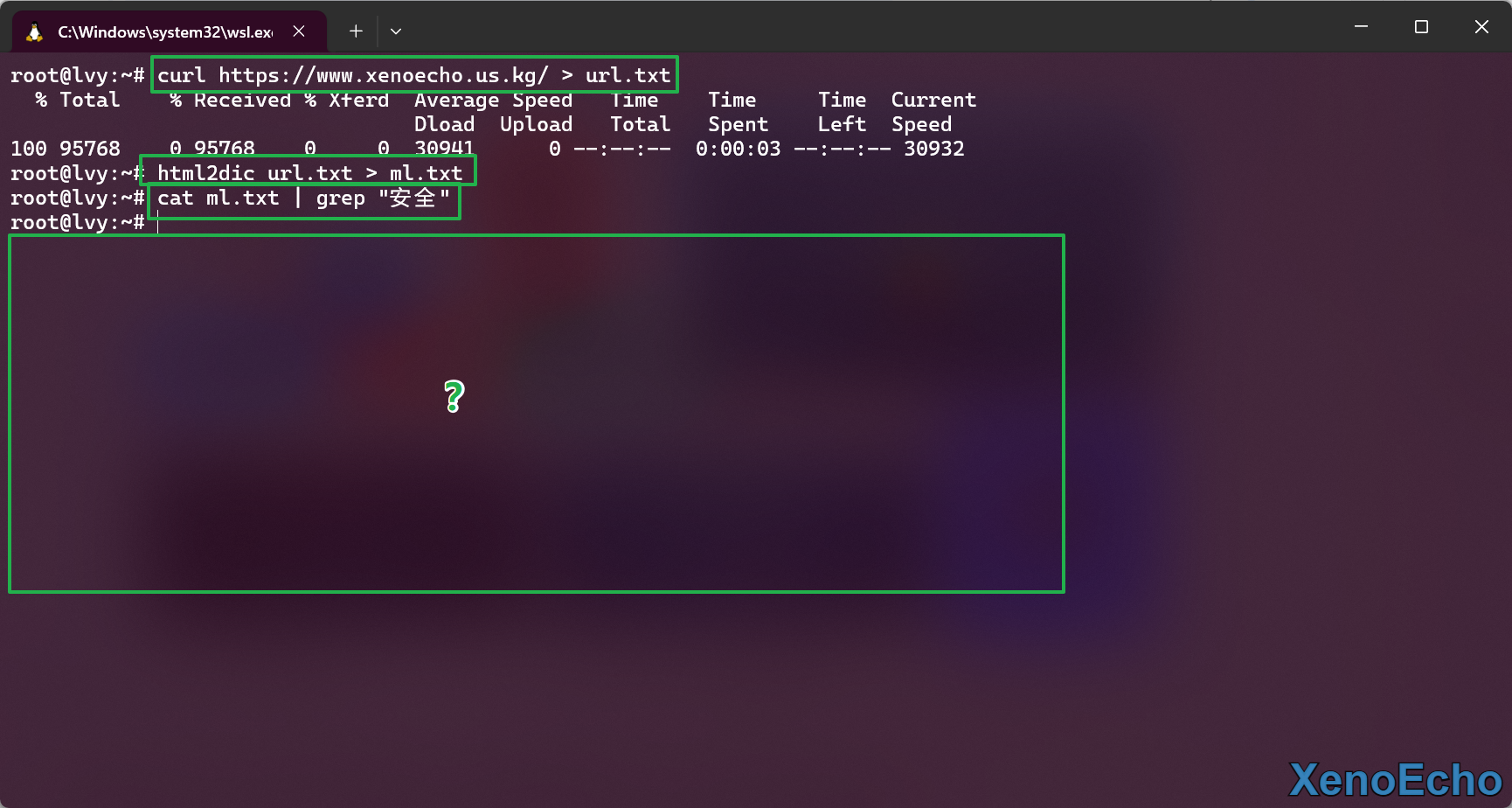
总结
印证了那句Dirsearch比较强大的话,配合一些自定义字典不比大部分目录枚举工具好用?而且配套的两个工具来说基本上很费,没什么很大用途主体本身也可以替代。以后目录枚举的话还是主用Dirsearch,要说还有个不错的用途话那就是Dirsearch配合
Dirb字典来用十分牛头人。
喜欢这篇的人也看了


评论 ()

学哲学的目的不是告诉你答案,而是告诉你去思考那些你原以为理所当然的事情。
XenoEcho
提出问题比找到答案更重要




